Looking for a NAS with built-in erasure coding? Check out StoneFly Super Scale Out (SSO) NAS!
Let’s elaborate it:
IT administrators who design storage systems must plan ahead so that mission critical data is not lost when any type of failure occurs. The storage systems comes in different shapes but they have one thing in common that is the chance of failing and losing data. The utilization of erasure coding prevents the loss of data due to system failure or disaster.
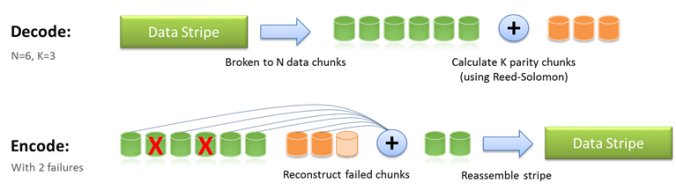
In simple words Erasure coding (EC) is one of the methods of data protection through which the data is broken into sectors. Then they are expanded and encoded with redundant data pieces and stored across different storage media. Erasure coding adds the redundancy to the system that tolerates failures.
Erasure coding takes original data and encodes it in such a way that, when you require the data it only needs the subset of the pieces to recreate the original information. Let’s take an example, consider that the original value of the object or data is 95, we divide it in such a way that x= 9 and y=5. The encoding process will create a series of equations.
Suppose in this case it will create equations like:
When you want to recreate the object you require any two of those three equations, to be able to be decoded. So when you solve the equations together, you will be able to get the values for x and y.
We have 3 equations but we can get the original information from two of them. The data protection scheme that breaks data into fragments, encodes them and stores them across multiple locations is Erasure coding.
Erasure coding and RAID are two different methods of protecting data. RAID (which stands for Redundant Array of Independent Disks) lets us save our data in multiple places so that if one or more disks fail, we still have copies of the data on other disks. Think of it like having multiple backpacks, each with a copy of your favorite toy. If one backpack gets lost or stolen, you still have other backpacks with the toy. RAID helps protect against losing your data when a disk fails.
Erasure coding is another way to protect data, but it works differently than RAID. With erasure coding, we break the data into smaller pieces, then we turn those pieces into something that looks different. It’s like taking a picture and cutting it into small squares, then rearranging the squares in a way that makes it hard to see the original picture. We then store these “coded” pieces in different places. If one or more places are lost or damaged, we can still use the other pieces to put the data back together. Erasure coding can help us protect against losing our data even if multiple disks fail.
While both RAID and erasure coding are used to protect data, they work differently and are good for different situations. RAID is good when we want to protect against losing data when one or more disks fail. Erasure coding is good when we want to protect against losing data even if multiple disks fail, and when we want to use less space to store our data.
Enterprises that require a failure free storage environment need to incorporate erasure coding technology. Here are some instances where EC can be very beneficial:
One common current use case for erasure coding is object-based cloud storage. As erasure coding requires high CPU utilization and incurs latency, it is suited for archiving applications. Erasure coding is less suitable for primary workloads as it cannot protect against threats to data integrity.
Erasure coding provides advanced methods of data protection and disaster recovery. StoneFly’s appliances use erasure-coding technology to avoid data loss and bring ‘always on availability’ to organizations. Erasure coding provides numerous benefits to its users.
Join our mailing list to receive the latest news, updates, and promotions from StoneFly.