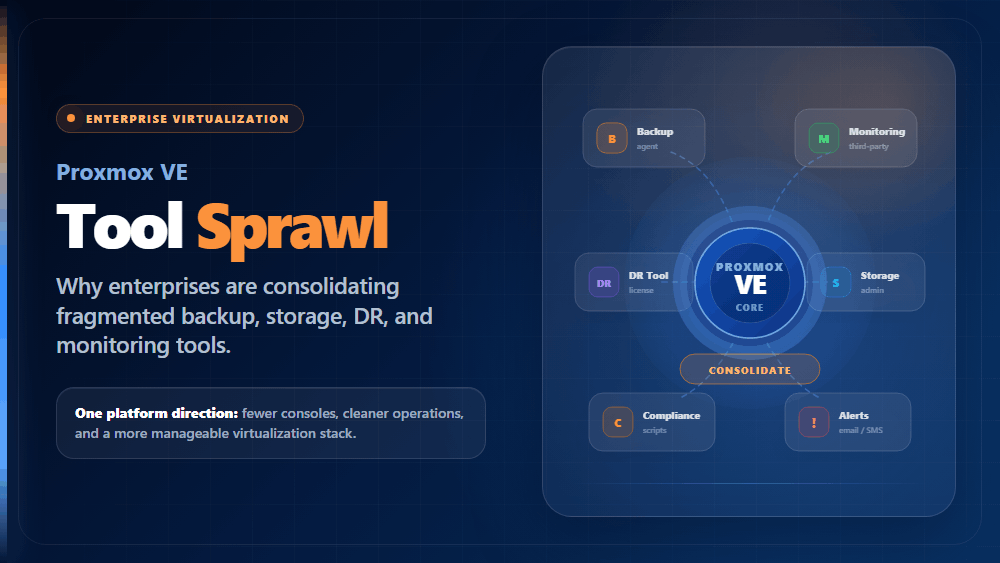
When a production database goes down, the recovery timeline is determined by decisions made long before the failure occurred. Database replication is the most direct architectural lever an enterprise has over that timeline — it determines how much data is at risk, how fast a standby can take over, and whether the failover is automatic or manual. Get the replication architecture right and a failure is a non-event. Get it wrong, and even a brief outage becomes a data loss incident.
The challenge is that “database replication” covers a wide range of architectures, methods, and deployment patterns that behave very differently under real-world conditions. Synchronous replication offers zero data loss but introduces write latency. Asynchronous replication scales across geography but introduces lag. Master-slave topologies simplify management but create a single write point. Multi-master architectures distribute writes but require conflict resolution. Each choice involves trade-offs, and those trade-offs depend entirely on the workload, geography, and recovery objectives of the environment.
This blog covers how database replication works at a technical level, the major replication methods and architectures enterprises use in production, and how to align replication strategy with high availability and disaster recovery requirements.
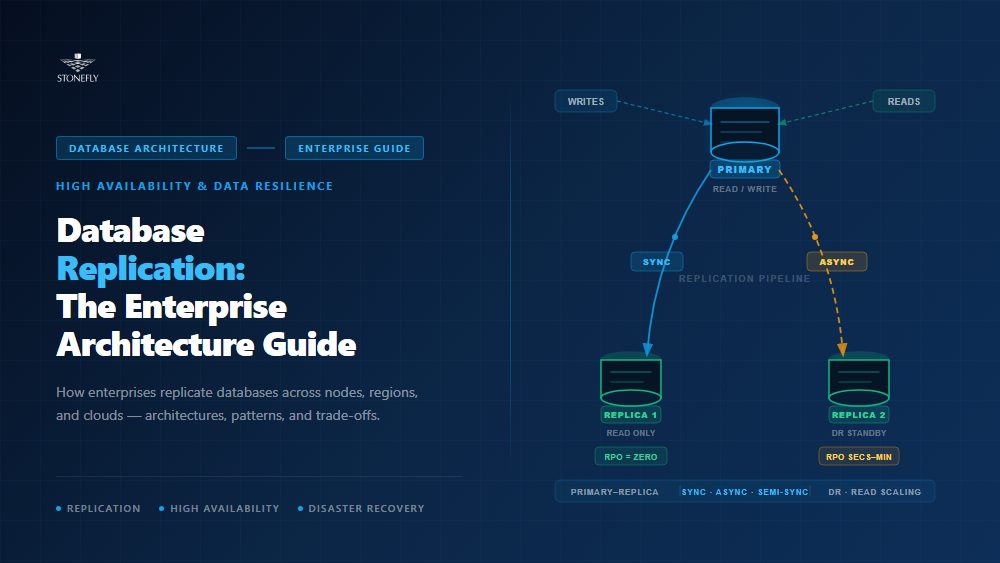
Database replication is the process of copying and synchronizing data from one database instance (the source or primary) to one or more additional instances (replicas or secondaries) in near-real-time or real-time. The goal is to maintain identical or consistent copies of data across multiple nodes, sites, or cloud regions so that if the primary fails, a replica can serve reads, accept writes, or both — depending on the replication architecture deployed.
Replication serves three distinct enterprise functions that are often conflated: high availability (keeping a standby ready to take over instantly), disaster recovery (maintaining a geographically separated copy for site-level failure), and read scaling (offloading read queries to replicas to reduce load on the primary). Each function has different latency, consistency, and topology requirements, which is why most production environments run more than one replication configuration simultaneously — for example, synchronous local replication for HA combined with asynchronous cross-region replication for DR.
Data redundancy in databases is not a nice-to-have. For regulated industries — financial services, healthcare, e-commerce — the combination of RPO (Recovery Point Objective, the maximum tolerable data loss) and RTO (Recovery Time Objective, the maximum tolerable downtime) are often contractual or regulatory requirements. Database replication is the primary mechanism for meeting both.
All database replication follows the same logical process: changes made on the source database are captured, transmitted to one or more replica nodes, and applied at the destination. The difference between replication implementations lies in how changes are captured, when they are transmitted, and how consistency is enforced across the replicated set. Understanding the database replication process at this level is essential for making informed architecture decisions.
The most common and performant approach to database replication is log-based change data capture (CDC). In this model, the database engine writes every committed transaction to a write-ahead log (WAL in PostgreSQL, binary log in MySQL, redo log in Oracle). The replication process reads this log stream and ships the change records to replica nodes, where they are replayed in order. Because the log is a complete record of all state changes — not just current data values — log-based replication can reconstruct the full transaction history at the replica and maintain strong consistency guarantees.
Log-based replication has low overhead because it operates on the log infrastructure the database engine already maintains for crash recovery. It captures all changes, including schema alterations and bulk operations, without requiring modifications to application code. Modern database replication software from vendors including Debezium, Attunity, and native database engines all use log-based CDC as their primary capture mechanism.
Trigger-based replication is an older database replication technique in which database triggers fire on INSERT, UPDATE, and DELETE operations and write change records to a staging table, which the replication engine then reads and forwards. It is more flexible than log-based replication in that it can replicate subsets of tables or rows based on conditions, but it adds overhead to every DML operation and cannot capture DDL (schema) changes directly. It is most commonly used in legacy environments or heterogeneous replication scenarios where source and target databases run on different engines.
Snapshot replication takes a point-in-time copy of the entire source database (or a subset) and ships it to replicas at a scheduled interval. It is suitable for read-only reporting replicas where slight data staleness is acceptable — for example, a nightly refresh of an analytics database from a production OLTP source. Snapshot replication is not suitable for high availability use cases because the snapshot interval creates a guaranteed data loss window equal to the interval duration.
The choice between synchronous and asynchronous replication is the single most consequential decision in database replication architecture. It determines the consistency guarantee between primary and replica and directly drives the RPO the architecture can achieve.
| Method | Commit Behavior | RPO | Latency Impact | Best For |
| Synchronous | Primary waits for replica acknowledgment before confirming commit | Zero (0 data loss) | High — adds replica round-trip to every write | Financial transactions, compliance workloads, same-datacenter HA |
| Asynchronous | Primary confirms commit immediately; replica applies changes independently | Seconds to minutes of lag | Minimal — no write penalty | Cross-region DR, read scaling, high-throughput OLTP |
| Semi-Synchronous | Primary waits for at least one replica to acknowledge receipt (not apply) | Near-zero (one write window) | Low to moderate | Most enterprise production workloads balancing safety and performance |
In synchronous replication, the primary database does not confirm a transaction to the client until at least one replica has confirmed it received and wrote the change. This guarantees that if the primary fails immediately after a commit, the replica holds the committed data — RPO is effectively zero. The cost is that every write incurs the round-trip latency to the replica. Over a LAN with sub-millisecond latency, this is negligible. Over a WAN between data centers in different cities, a 20–50ms round-trip can reduce write throughput by 50–80% on latency-sensitive workloads.
Synchronous replication is appropriate for co-located high availability pairs — primary and standby in the same data center on a fast fabric — and for financial, healthcare, or e-commerce workloads where even a single committed transaction cannot be lost. PostgreSQL’s synchronous_commit parameter, MySQL Group Replication in single-primary mode, and Microsoft SQL Server’s synchronous-commit availability groups all implement this model.
Asynchronous replication allows the primary to commit transactions and immediately confirm them to the client, with replica updates happening independently and slightly behind. The primary maintains a replication queue; replicas consume it at their own pace. The gap between what is committed on the primary and what has been applied at the replica is the replication lag — typically milliseconds on a healthy local setup, but potentially seconds or minutes under heavy write load or high-latency WAN links.
Asynchronous replication is the standard approach for cross-region database disaster recovery because the latency of synchronous commits over WAN distances would make most production workloads unacceptably slow. It is also the default configuration for read replicas in distributed database systems — replicas that exist to offload SELECT queries from the primary. The trade-off is that if the primary fails before the replica has applied all pending changes, those changes are lost. The RPO equals the replication lag at the time of failure.
Semi-synchronous replication is a middle-ground approach where the primary waits only for acknowledgment that a replica has received the change record — not that it has applied it. This eliminates the full apply latency of synchronous replication while still ensuring that committed transactions exist on at least two nodes before the client receives confirmation. Under normal conditions, the window for data loss is limited to whatever the replica had received but not yet applied — typically a very small number of transactions.
MySQL’s semi-synchronous replication plugin is a common production implementation. Many enterprise database replication solutions default to semi-synchronous for primary-replica pairs within a data center, treating it as the practical default for workloads that need better durability than async without the write performance cost of full synchronous commits.
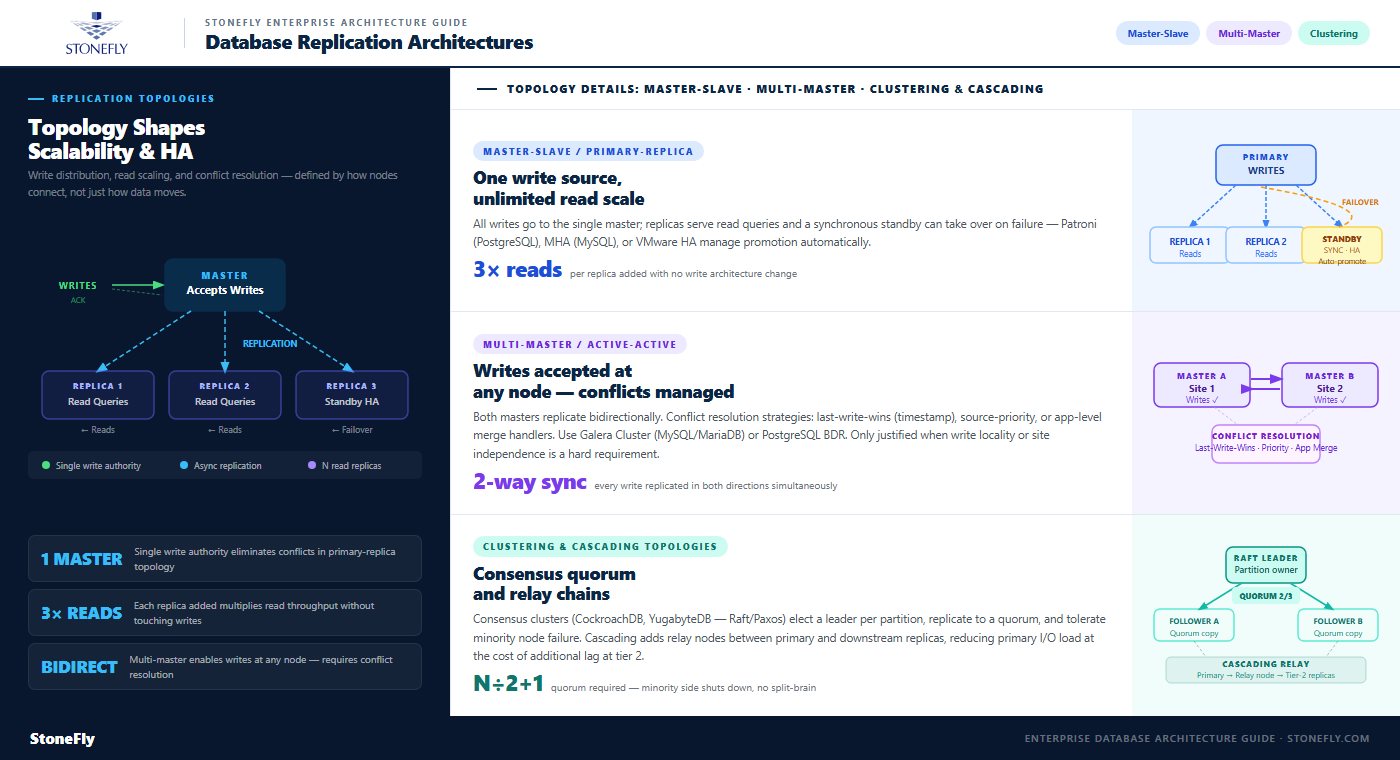
Replication method (synchronous vs. asynchronous) determines consistency behavior. Replication topology — the arrangement of sources and replicas — determines scalability, write availability, and operational complexity. The right topology depends on whether the environment prioritizes read scaling, write distribution, or geographic redundancy.
Master-slave replication (also called primary-replica or leader-follower replication) is the most common database replication architecture in production. A single master node accepts all write operations. One or more slave nodes receive and apply changes from the master and serve read queries. Because writes flow in one direction only, conflict resolution is not required — there is a single authoritative source of truth for write operations.
For read-heavy workloads like web applications, adding read replicas allows horizontal scaling of SELECT query capacity without modifying application architecture. Three replicas serving reads can triple the read throughput of the cluster without changing how writes work. For high availability, a standby replica kept in synchronous replication mode can take over as master automatically if the primary fails, with automated failover managed by orchestration tools like Patroni (PostgreSQL), MHA (MySQL), or native database clustering.
Multi-master replication (also called active-active replication) allows multiple nodes to accept write operations simultaneously. Changes are replicated bidirectionally — each master sends its writes to all other masters and applies their incoming changes. This architecture enables writes to continue at any node during a network partition or node failure, making it valuable for geographically distributed applications where users in different regions need to write to a local node with low latency.
The complexity of multi-master replication lies in conflict resolution: if two nodes independently modify the same row at the same time, the system must decide which change wins. Resolution strategies include last-write-wins (based on timestamp), source-priority rules, or application-level conflict handlers. Galera Cluster (for MySQL/MariaDB) and PostgreSQL BDR (Bi-Directional Replication) are widely used multi-master implementations in enterprise environments. The operational overhead of managing conflicts makes multi-master architecture appropriate only when write locality or write availability across independent sites is a hard requirement.
Database clustering extends replication into a shared-resource model where multiple nodes access the same underlying storage (as in Oracle RAC) or tightly coordinate writes through a distributed consensus protocol (as in CockroachDB or YugabyteDB). Distributed database systems built on consensus protocols like Paxos or Raft elect a leader for each data partition, replicate writes to a quorum of nodes, and can tolerate minority node failures without data loss or service interruption.
Cascading replication topologies introduce intermediate relay nodes between the primary and downstream replicas. A relay node receives changes from the primary and forwards them to a second tier of replicas. This reduces the network and I/O load on the primary — which would otherwise maintain direct replication connections to dozens of downstream nodes — at the cost of introducing additional replication lag at the second tier. Cascading topologies are common in large-scale analytics environments where many read replicas serve different regional audiences.
Real-time database replication and continuous data protection (CDP) are related but distinct. Standard database backup strategies — nightly full backups, hourly incrementals — create recovery points at fixed intervals. A failure between backup windows means data loss equal to the time since the last backup: potentially hours. Continuous data protection eliminates that window by capturing every change as it happens and maintaining a complete, recoverable change history.
True CDP systems record every write operation to a separate change log that can be replayed to any point in time — not just to the last backup snapshot. This makes CDP the appropriate choice for databases with strict RPO requirements measured in seconds or less. It also protects against logical corruption: if a bad DELETE or erroneous UPDATE is executed on the primary, a CDP system allows recovery to the exact second before that operation, rather than to the previous backup point which may be hours earlier.
Database mirroring is a specific SQL Server feature (deprecated in favor of Always On Availability Groups) that maintained a synchronized copy of a database on a mirror server. Unlike general replication, mirroring operated at the database level rather than the row or object level, transmitting the full transaction log in synchronous or asynchronous mode. The key difference from standard replication is that database mirroring did not support read operations on the mirror — it was exclusively a failover mechanism, not a read-scaling or analytics offload tool.
Modern real-time database replication tools support both use cases simultaneously: a synchronous replica that serves as a hot standby for automatic failover and also serves read queries during normal operation. This dual-purpose model reduces infrastructure cost compared to maintaining dedicated failover nodes that serve no operational purpose until a failure occurs.
High availability database design requires more than just a running replica — it requires a reliable mechanism for detecting primary failure and promoting a replica to primary without human intervention, and without creating a split-brain condition where two nodes both believe they are the primary and independently accept writes. High availability database solutions use a combination of replication, health monitoring, and fencing (STONITH — Shoot The Other Node In The Head) to prevent split-brain.
Tools like Patroni, orchestrating PostgreSQL via etcd or Consul for distributed consensus, provide automatic leader election and failover with configurable synchronous replication requirements. A cluster configured to require synchronous acknowledgment from at least one replica before committing guarantees that the promoted replica holds all committed data. Applications connect through a virtual IP or load balancer endpoint that the orchestrator updates to point to the new primary — failover completes without application reconfiguration.
Database disaster recovery via replication requires matching the replication configuration to the organization’s RPO and RTO commitments. An RPO of zero requires synchronous replication — which means the DR site must be close enough (network latency under ~5ms) that synchronous commits don’t degrade write performance. An RPO of 15 minutes allows asynchronous replication to a geographically distant DR site, with the understanding that up to 15 minutes of committed transactions could be lost in a catastrophic failure.
RTO is driven by how quickly the DR replica can be promoted and how quickly applications can be redirected to it. Warm standby configurations — replicas continuously receiving changes and ready to accept traffic immediately — can achieve RTO in the 30–120 second range with automated failover orchestration. Cold standby configurations — replicas that need to be started, validated, and promoted manually — extend RTO to hours. The choice of database backup strategies, backup and recovery procedures, and replication topology together determine the actual RTO achievable in practice.
Cloud database replication introduces a layer of complexity that on-premises replication does not: variable network latency, cloud provider-specific replication services, and the need to replicate across environments that may use different database engines or storage backends. Most cloud providers offer managed replication for their native database services — AWS RDS Multi-AZ, Azure SQL Database’s Active Geo-Replication, Google Cloud SQL’s cross-region replicas — but these services operate within the provider’s ecosystem and do not extend seamlessly to on-premises or competing cloud environments.
Hybrid cloud database replication — maintaining replicas on-premises and in one or more cloud regions — is the architecture most large enterprises actually need. It requires database replication tools that operate independently of the underlying cloud infrastructure: log-shipping over encrypted tunnels, replication agents that run on the source and target regardless of where they are deployed, and change data capture pipelines that can bridge heterogeneous environments (for example, replicating from an on-premises Oracle database to an AWS Aurora PostgreSQL target). Latency, bandwidth costs, and network reliability are more variable in cloud and hybrid environments, making asynchronous replication with lag monitoring the standard approach for cross-site and cross-cloud replication.
Cloud database replication also intersects with database scaling strategies. Read replicas in a cloud environment can be provisioned and deprovisioned dynamically in response to load — scaling out read capacity during peak periods and releasing it during off-hours. This elasticity is not available in traditional on-premises replication environments and represents a genuine operational advantage of cloud-native replication architectures.
Database replication delivers clear benefits, but each benefit comes with operational and architectural trade-offs that need to be understood before deployment. The following table summarizes the primary advantages and disadvantages of database replication as deployed in enterprise production environments.
| Advantage | Description | Corresponding Challenge |
| High availability | Replicas provide instant failover targets, reducing downtime to seconds in automated configurations | Failover orchestration requires careful tuning to avoid false positives and split-brain |
| Disaster recovery | Off-site replicas protect against site-level failures and ransomware events that destroy local copies | Asynchronous replication to DR sites introduces data loss risk equal to the replication lag |
| Read scaling | Read queries can be distributed across replicas, increasing read throughput without additional primary hardware | Applications must be designed to route read and write traffic to the correct endpoints |
| Data redundancy | Multiple copies of data reduce the risk of permanent data loss from hardware failure | More copies increase storage costs and introduce complexity in ensuring all copies remain consistent |
| Geographic distribution | Local replicas serve users in different regions with low-latency reads | Multi-master write distribution requires conflict resolution logic and careful schema design |
| Reduced backup window impact | Backups can run against a replica rather than the primary, eliminating backup-related load on production | Replicas used for backups may have slightly stale data — backup strategy must account for this |
Enterprise database replication strategies are only as strong as the underlying storage and data protection infrastructure that supports them. Replication protects against database-level failures and provides the read-scaling and failover architecture databases need — but it does not replace storage-level backup, immutable snapshots, or air-gapped protection against ransomware events that target both the primary database and its replicas simultaneously.
StoneFly’s DR365V delivers the complementary layer that database replication alone cannot provide: air-gapped, immutable backup repositories that ransomware cannot reach even if it compromises every node in a database replication cluster. The DR365V integrates with Veeam to capture database-consistent backup jobs, stores them in WORM-protected immutable repositories, and maintains a copy isolated from the production network — so that even if a coordinated attack encrypts both the primary database and its synchronous replica, a clean recovery point exists outside the blast radius.
For organizations running scale-out database environments, StoneFly’s USO (Unified Scale-Out SAN, NAS, and S3 Object Storage) provides the high-throughput, low-latency storage backend that database replication demands. Synchronous replication is only as fast as the storage layer confirming writes — NVMe-backed USO volumes reduce the write latency that makes synchronous commits expensive, allowing synchronous replication configurations that would be impractical on slower storage. The USO also supports database snapshot integration for point-in-time recovery independent of the replication topology.
Database replication is not a configuration choice — it is an architecture decision with consequences that reach into every aspect of how an enterprise database environment handles failure, scales under load, and recovers from incidents. The difference between synchronous and asynchronous replication is the difference between zero data loss and minutes-to-hours of exposure. The difference between master-slave and multi-master topologies is the difference between operational simplicity and geographic write availability. Getting those choices right requires matching the replication architecture to the specific recovery objectives, latency constraints, and workload characteristics of each database environment.
The most resilient enterprise database environments combine two things: a replication architecture sized to the HA and DR requirements of the workload, and a storage-level data protection layer that remains recoverable even when the replication topology is compromised. Database replication handles the operational availability use case. Immutable, air-gapped backup handles the catastrophic failure and ransomware use case. Both are required. Neither is sufficient alone.
Contact StoneFly to discuss how DR365V and USO integrate with your database replication architecture to close the data protection gaps that replication alone cannot address.











Join our mailing list to receive the latest news, updates, and promotions from StoneFly.