


On October 20, 2025, AWS US-East-1 — the busiest cloud region in the world — went down for roughly 15 hours. A DNS failure affecting the DynamoDB API endpoint cascaded across more than 3,500 companies in over 60 countries, taking down everything from Snapchat and Coinbase to enterprise SaaS platforms. None of those organizations did anything wrong, technically. They simply kept every copy of their data and every running workload in one region — and that region failed. Any single site, no matter who operates it, is a single point of failure.
Geo redundant storage exists because the economics of downtime no longer tolerate that exposure. In ITIC’s hourly cost of downtime surveys, 41% of enterprises report that a single hour of downtime costs $1 million or more. Regulators have caught up too: the EU’s Digital Operational Resilience Act (DORA), which took effect in January 2025, requires financial entities to prove they can withstand and recover from ICT disruptions — a bar that’s hard to clear when all production and backup data shares one disaster domain.
This blog explains what geo redundancy is, how cross region replication actually moves data between geo redundant data centers, why backup and redundancy are two different disciplines, and how to implement geo-redundancy in data centers without overspending on bandwidth or idle infrastructure.
Geo redundancy is the practice of maintaining complete copies of data and infrastructure in two or more data centers located in separate geographic regions. If a regional disaster — power grid failure, flood, fire, or network outage — takes one site offline, a geographically redundant copy continues serving data from another region with little or no interruption.
That definition answers the “what is geo redundancy” question, but the operative word is geographic. Plenty of organizations already run redundant storage: RAID arrays, mirrored controllers, clustered nodes. Those mechanisms protect against component failure inside a single facility. Geo redundant storage extends that same principle of redundant data storage across regions, so the failure of an entire site — not just a disk or a node — becomes a survivable event.
The useful mental model is the disaster domain: the geographic and infrastructural blast radius within which a single event can destroy or disconnect everything. Two storage arrays in the same server room share a disaster domain. Two data centers on the same metro power grid still share one. Genuine geographic redundancy requires that each copy of the data sits in a location with independent power, independent network paths, and independent exposure to natural hazards — typically a different city or region entirely.
This is why data storage redundancy planning starts with a map, not a product sheet. A second site 10 miles away protects you from a building fire but not from a hurricane, an earthquake, or a regional grid collapse. Most enterprise architects target sites far enough apart that no single plausible event touches both.
Data center redundancy — N+1 power feeds, redundant cooling, dual network carriers, Uptime Institute tier ratings — hardens a single facility against internal failures. It is necessary, but it is not geo redundancy. The October 2025 AWS incident is the proof: US-East-1 is built from some of the most redundant facilities on earth, and a region-level control-plane fault still took workloads offline for the better part of a day.
Geo redundant data centers solve a different problem. Instead of making one site harder to kill, they make the architecture indifferent to the death of any one site. The two approaches are complementary: facility-level data center redundancy reduces the frequency of failover events, while geographic redundancy makes the rare region-wide event recoverable.
Region-scale failures are not hypothetical, and they are not limited to weather. The March 2021 OVHcloud fire in Strasbourg destroyed an entire data center building; customers whose only copies lived in that facility lost data permanently. The 2025 outage record added new failure modes: AWS’s 15-hour US-East-1 event, and Cloudflare incidents in November and December 2025 that disrupted a significant share of global HTTP traffic for hours. In each case, organizations with a geographically redundant copy of their data and a tested failover path kept operating. Those without one waited.
Compliance frameworks increasingly assume geographic redundancy rather than merely encouraging it. DORA requires EU financial entities to demonstrate ICT resilience and tested recovery. HIPAA’s contingency planning rule expects healthcare organizations to maintain retrievable, exact copies of ePHI. FFIEC guidance for financial institutions has long pushed for out-of-region recovery capabilities. Cyber insurers, meanwhile, ask pointed questions about offsite copies before writing or renewing policies.
Concretely, geographic redundancy is the only architectural answer to these failure classes:
Cross region replication is the automated, continuous copying of data from storage in one region to storage in another, so that a current (or near-current) copy always exists outside the primary disaster domain. It is the engine that makes geo redundant storage work — whether implemented as AWS S3 Cross-Region Replication, Azure geo-redundant storage (GRS), or appliance-to-appliance replication between your own geo redundant data centers. (For a deeper primer on the underlying mechanics, see StoneFly’s guide to data replication technology.)
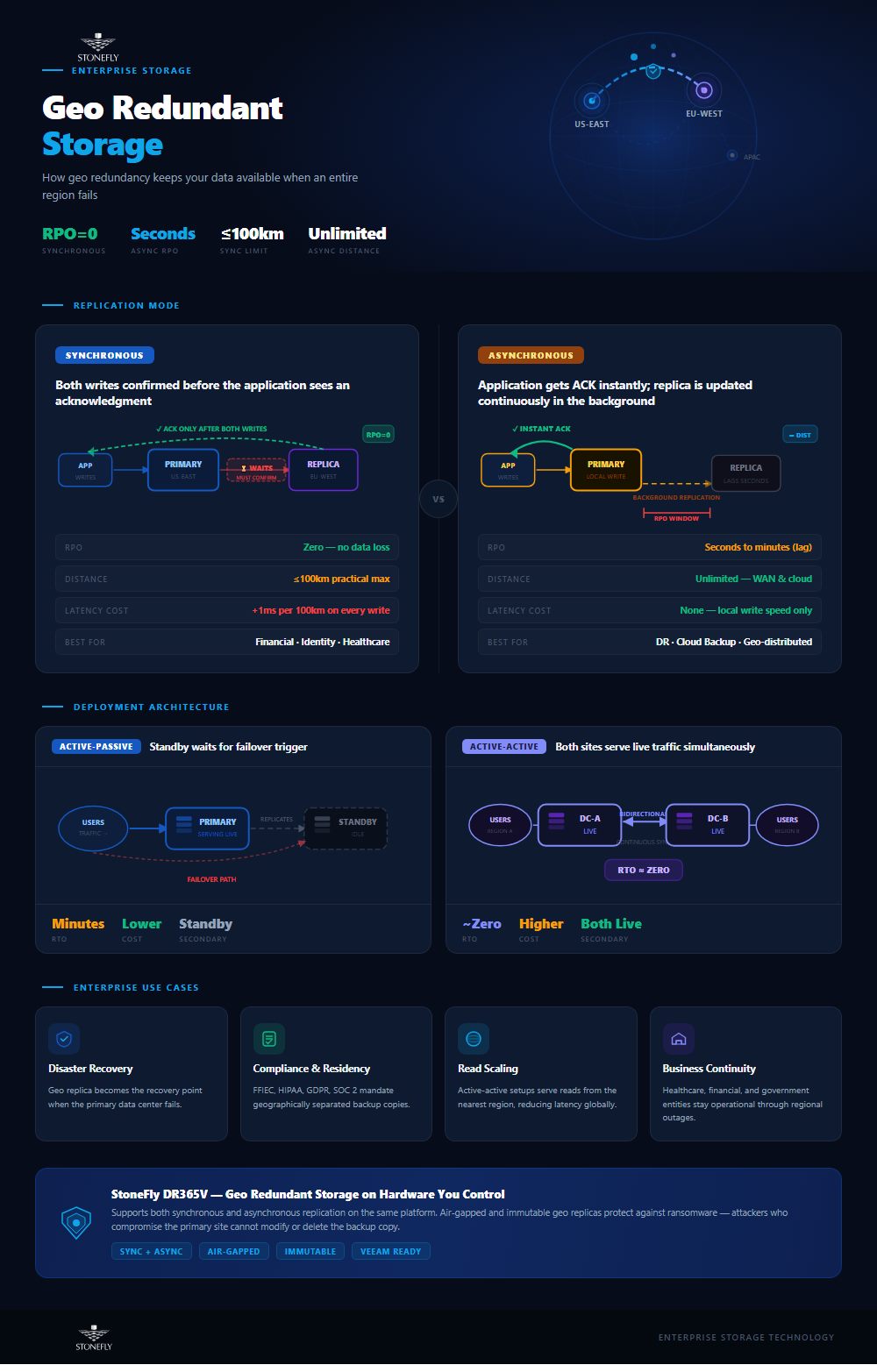
Every cross data center replication design makes one fundamental choice: does the application wait for the remote copy to be written, or not? That single decision — synchronous versus asynchronous — determines your recovery point objective (RPO), your latency budget, and how far apart your sites can be.
In synchronous replication, every write is committed at both sites before the application receives an acknowledgment. The two copies are identical at all times, which means an RPO of zero — a site failure loses no committed data. This is real time data replication in the strictest sense, and it’s the standard for transaction-critical workloads such as financial databases.
The cost is physics. Light in fiber adds roughly one millisecond of round-trip latency for every 100 km of site separation, and every acknowledged write pays that tax. In practice, synchronous replication is deployed between sites within metro or regional distances, which limits how much geographic separation it can provide. Many architectures pair synchronous replication to a nearby site with asynchronous replication to a distant one.
Asynchronous replication commits writes locally first, then ships changes to the remote site on a continuous or scheduled basis. Because the application never waits on the WAN, sites can be separated by thousands of miles with no impact on production performance. The trade-off is a non-zero RPO: the remote copy lags by seconds to minutes, and a sudden primary-site failure loses whatever hadn’t yet replicated.
Managed cloud implementations behave the same way. Microsoft documents that Azure GRS replicates asynchronously to a fixed paired region with a typical RPO under 15 minutes — but offers no SLA on that figure. Sizing matters too: your replication bandwidth must sustain your data change rate, or the lag (and your effective RPO) grows unbounded during busy periods.
Cloud providers package data storage redundancy into named tiers, and the differences matter more than the marketing suggests. Here’s how the common options compare:
| Redundancy option | Where the copies live | Protects against | Typical RPO |
| Locally redundant storage (LRS) | 3 copies in one data center | Drive and node failure | Zero (synchronous) |
| Zone-redundant storage (ZRS) | 3 availability zones in one region | Loss of a data center | Zero (synchronous) |
| Geo-redundant storage (GRS / GZRS) | Primary region + fixed paired region | Regional outage | Minutes (async; typically <15 min, no SLA) |
| S3 Cross-Region Replication (CRR) | Buckets in regions you choose | Regional outage; sovereignty requirements | Seconds to minutes (async) |
| On-prem / hybrid cross data center replication | Your own sites, colo, and/or cloud | Regional outage and provider-level failure | Configurable: zero (sync) to minutes (async) |
One nuance buried in the documentation: with Azure GRS, the secondary copy is not readable during normal operation, and becomes accessible only after a failover is initiated. Architectures that assume they can serve reads from the secondary region need read-access GRS (RA-GRS) or an application-level replication design. If you’re weighing managed replication against do-it-yourself copying, StoneFly’s comparison of AWS S3 replication vs. copying breaks down where each fits.
Here is the mistake that costs organizations their data: treating replication as a backup. Cross region replication is faithful by design — it copies everything, including the things you wish it wouldn’t. When ransomware encrypts your file shares, real time data replication ships those encrypted blocks to your second site within seconds. When an administrator deletes a volume, the deletion replicates too. Geo redundancy protects against infrastructure loss; it does nothing against data corruption, because the corruption simply becomes geographically redundant.
Backup solves the problem replication can’t: it preserves point-in-time history. A versioned, immutable backup lets you roll back to the moment before the encryption event or the deletion, regardless of what has replicated since. That’s why mature architectures treat backup and redundancy as separate layers — replication for availability, backup for recoverability. (StoneFly’s comparison of mirroring vs. replication vs. clustering maps where each technique belongs.)
The two layers converge in geo-redundant backup storage: applying geographic redundancy to the backup tier itself. The classic 3-2-1 rule — three copies, two media types, one offsite — is the minimal form. The modern extension, 3-2-1-1-0, adds one air-gapped or immutable copy and zero errors on recovery verification. An offsite backup copy that ransomware can reach over the network is offsite in geography only; pairing geographic separation with air-gapping and immutability is what makes the backup tier genuinely unreachable. How backup and redundancy fit into a broader continuity program is covered in StoneFly’s guide to business continuity vs. disaster recovery.
Knowing how to implement geo-redundancy in data centers comes down to three decisions made in the right order: where the sites are, how data moves between them, and how failover is proven. Get the sequence wrong — picking a replication product before defining RPO/RTO targets, for example — and you either overspend or underprotect.
Start by defining the disaster domains you must survive, then place sites accordingly. The second site needs an independent power grid, independent network carriers, and no shared exposure to flood plains, seismic zones, or hurricane tracks. At the same time, distance is a latency budget: if any workload requires synchronous, zero-RPO replication, the site pair must stay within metro-scale distances, with a third, distant site handling asynchronous copies.
The second “site” doesn’t have to be a building you own. A colocation cage, a cloud region, or a hybrid of both can serve as the geographically redundant target — often at a fraction of the capital cost of a second owned facility. What matters is disaster-domain independence and sufficient bandwidth, not ownership.
With sites chosen, match the topology to your recovery objectives:
Whatever the topology, size replication bandwidth against your peak data change rate, not your average — and account for initial seeding, which for large datasets may justify physical data transfer before continuous replication takes over.
An untested failover plan is a hypothesis. Document runbooks that cover detection, decision authority, DNS or IP failover, application restart order, and — critically — failback. Then test on a schedule: tabletop walkthroughs quarterly, live failover of representative workloads at least annually. Each test should measure actual RTO and RPO against targets, because the gap between assumed and measured recovery times is where continuity plans fail.
Testing is also where the backup-versus-redundancy distinction becomes operational. A failover test validates your geographic redundancy; a recovery test validates your backups. Run both, because each covers a failure class the other cannot.
StoneFly builds the replication and backup layers described above into a single portfolio, deployable as physical appliances, virtual machines, or cloud instances. StoneFly’s USO (Unified Scale-Out) storage appliances and SCVM software-defined storage support both synchronous and asynchronous volume replication, enabling cross data center replication between StoneFly systems at your sites — or to Azure and AWS via StoneFly Cloud Connect when the second disaster domain is a cloud region rather than a building.
For the backup tier, the StoneFly DR365V Veeam-ready backup and DR appliance combines backup and redundancy in one architecture: backups land in air-gapped, immutable repositories that ransomware can’t reach or modify, and the appliance replicates those backups to a second DR365V at a remote site or to the cloud. The result is geo-redundant backup storage with deletion protection and automated air-gapping managed directly from the Veeam console — point-in-time recoverability and geographic redundancy in the same system, rather than two products stitched together.
Because every StoneFly system runs the same StoneFusion storage operating system, organizations can start with a single appliance pair and scale toward multi-site, hybrid-cloud geo redundancy without re-architecting.
The 2025 outage record settled the argument: regional failures happen to the most sophisticated operators in the industry, and the only architectures that shrugged them off were geographically redundant ones. Geo redundancy is no longer a luxury line item — it is the baseline assumption behind modern compliance frameworks, cyber insurance underwriting, and board-level resilience questions.
The design principles are stable. Separate your copies by disaster domain, not just by rack. Choose synchronous or asynchronous cross region replication based on measured RPO requirements and the physics of distance. And never confuse replication with backup — pair geo redundant storage for availability with immutable, geo-redundant backup storage for recoverability, then test both until the runbooks are boring.
To talk through replication topologies, RPO/RTO targets, or a geo redundant storage deployment sized to your environment, contact StoneFly at [email protected].











Join our mailing list to receive the latest news, updates, and promotions from StoneFly.


