Enterprise data environments are growing more complex, with expanding databases, distributed systems, and hybrid cloud infrastructures. This complexity increases the risk of data corruption, accidental deletion, and ransomware attacks. Traditional backup methods often fall short because they capture data at fixed intervals, leaving organizations vulnerable to losing valuable transactions when restoring from the most recent backup. As a result, enterprises now view Point-in-Time Recovery (PITR) as a vital component of their data protection plans.
Databases running mission-critical applications—such as financial platforms, healthcare systems, and logistics operations—must remain reliable and consistent. A single corruption event or user mistake can halt operations and cause significant losses. Point-in-time recovery gives organizations the precision to restore databases to the exact moment before an incident occurred.
The point-in-time recovery concept refers to restoring data from any chosen moment in the past within the backup retention period. This method helps organizations meet strict Recovery Point Objective (RPO) targets, minimizing data loss while supporting compliance and business continuity. Unlike full database restores, which revert entire datasets, point-in-time restore allows fine-grained recovery at the transactional level.
A point-in-time database configuration uses continuous transaction logging and backup snapshots, enabling the recovery of specific database states. For example, with cloud SQL point-in-time recovery or RDS point-in-time restore, enterprises can revert data to a precise timestamp just before an unwanted transaction occurred. This level of recovery accuracy is essential for maintaining data integrity.
A well-implemented point-in-time architecture integrates backup and recovery processes with broader business continuity efforts. The ability to restore to a specific point in time helps limit downtime and supports continuous access to critical applications. Combining point-in-time backup solutions with automated failover systems further accelerates recovery during outages or disruptions.
Adopting these strategies helps enterprises uphold service-level agreements (SLAs), protect customer confidence, and maintain compliance with governance standards. This blog covers how point-in-time recovery functions at an architectural level, how to configure point-in-time backups in cloud-based databases, and why selecting the right retention policy is key to long-term protection against data loss.
By the end, IT leaders will gain a clear understanding of what point-in-time restore is, how it differs from traditional backups, and the measurable benefits it brings to a complete data protection strategy.
Data loss in enterprise systems often stems from human error, corrupted transactions, or accidental overwrites rather than hardware failures. In such situations, restoring an entire system from a traditional backup isn’t always practical. Point-in-Time Recovery (PITR) provides a more precise solution. It enables administrators to roll back data to the exact state it was in at a specific moment before the issue occurred, reducing downtime and preventing unnecessary data loss.
The main concept behind point-in-time recovery is the ability to restore data to a selected moment instead of reverting only to the last backup. Enterprise databases, such as those running on SQL servers or cloud platforms like Cloud SQL or Amazon RDS, continuously record transactional logs. These logs track every change — including insertions, updates, and deletions — allowing administrators to replay operations up to the desired recovery time.
This process forms the basis of a point-in-time recovery architecture. In this setup, the database maintains layers of recoverability: a full backup as the foundation, scheduled incremental backups, and continuous logs that record ongoing changes. When data corruption or user mistakes occur, the administrator starts a point-in-time restore, specifying the exact timestamp to recover. The system replays the log data to reconstruct the database state just before the problem took place.
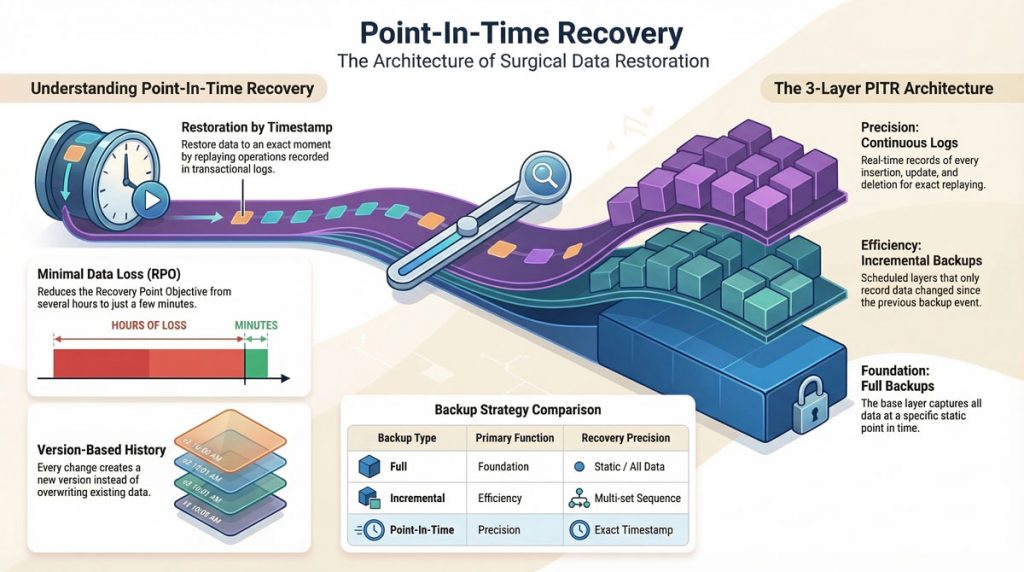
Each type of backup plays a specific role in a data protection strategy:
This method offers flexibility and precision. Organizations can align recovery processes with their Recovery Point Objective (RPO) — the maximum acceptable data loss window. With a point-in-time backup strategy, the RPO can often be shortened from hours to minutes.
Consider a financial institution processing thousands of transactions per minute. If a faulty script updates account balances incorrectly, restoring from the previous night’s backup would wipe out legitimate transactions. Instead, administrators can restore to a point in time just before the error occurred, keeping valid data intact and removing only the faulty changes.
Manufacturing and logistics operations face similar risks. A single misconfigured application could overwrite workflow or production data critical to daily operations. Using a point-in-time restore, teams can revert systems to a specific checkpoint with minimal downtime, avoiding disruptions and inaccurate reporting.
Cloud-based environments like RDS point-in-time restore and cloud SQL point-in-time recovery extend these advantages across hybrid and multi-cloud deployments. Businesses can maintain data consistency, meet compliance goals, and ensure availability without depending solely on local infrastructure.
In essence, point-in-time recovery gives enterprises greater control over their data. By enabling restoration to the precise moment before an error, it strengthens resilience, supports compliance, and safeguards uninterrupted business operations.
An effective point-in-time architecture is built on data versioning. Each change creates a new version rather than overwriting the existing data, forming a complete history of states. This allows teams to move through data timelines and select an exact version for restoration.
Within a point-in-time database, version control supports both analytics and recovery. For example, when database engines log changes using write-ahead logs (WAL) or similar journaling tools, they retain a record of events that can be replayed up to the desired point of recovery.
Versioning also improves recovery efficiency. Instead of restoring the entire database, administrators can roll back a specific schema, table, or record range, saving time and limiting downtime. Modern storage technologies, including StoneFly’s enterprise appliances, employ version-aware retention policies to make snapshots both space-efficient and quick to recover.
At the core of a point-in-time recovery process is the ongoing capture of data changes. Enterprise databases and storage systems record every transaction, update, and modification in transaction logs or journal files, which serve as a chronological record of operations. Alongside these logs, regular snapshots or point-in-time backups provide full or incremental copies that serve as recovery anchors.
For example, in an enterprise database environment, snapshots might be taken every four hours, while transaction logs record activity every few seconds. If corruption occurs at 3:25 p.m., administrators can restore the database to the last stable state—say, 3:15 p.m.—resulting in minimal data loss.
Step 1: Identify the Event and Select the Recovery Point
Recovery begins by pinpointing when the disruption occurred. Based on the designated RPO, administrators choose the moment before the issue arose. In cloud SQL or RDS environments, this is typically done through management consoles with timestamp-based restore options.
Step 2: Retrieve the Base Snapshot or Backup
The most recent scheduled snapshot or backup is retrieved to serve as the foundation for recovery. In enterprise environments, these snapshots are often stored on high-performance storage tiers for faster restoration.
Step 3: Apply Transaction Logs or Journal Files
Once the base snapshot is loaded, the system replays all transactions recorded after that snapshot up to the selected timestamp. This recreates the exact data state from the chosen point in time.
Step 4: Validate and Reintegrate the Restored Data
After replaying the logs, validation and consistency checks are performed. Checksums, referential integrity checks, and transaction boundary verifications ensure the restored data aligns with business rules and application logic. Depending on internal policy, restored data may first be verified in a staging environment before being brought back to production.
Consider a financial institution operating a multi-region ERP database in the cloud. During a faulty application update, one of the transaction tables becomes corrupted at 9:42 a.m. The IT team isolates the affected instance and initiates a point-in-time restore.
Using automation within their backup management platform, they select the consistent backup from 9:00 a.m. and replay journal files through 9:39 a.m. Once validation confirms data integrity, the restored environment replaces the corrupted instance. Within an hour, the database is fully operational, with less than three minutes of transaction data lost—well within acceptable RPO limits.
For enterprises processing large volumes of transactions, a well-structured point-in-time recovery framework is more than a set of storage snapshots—it is a continuously coordinated system of backup policies, journaling, and validation procedures. Each restore must factor in log retention, snapshot schedules, and cloud API integrations to guarantee a reliable, automated recovery process.
A deep understanding of point-in-time recovery allows architects and data engineers to design systems that minimize downtime, prevent data loss, and support enterprise-level governance and compliance standards. With the right configuration and automation in place, organizations can maintain resilience and confidently recover from unexpected disruptions.
Point-in-Time Recovery (PITR) is now a core requirement for enterprises aiming to strengthen data protection across hybrid infrastructures. Whether databases are hosted on physical servers, virtual machines, or managed cloud services, restoring data to a precise moment before an incident—such as corruption, accidental deletion, or a cyberattack—helps maintain continuity and meet compliance standards.
At its core, point-in-time recovery allows a database to be restored to its exact state at a chosen timestamp. This supports more stringent Recovery Point Objectives (RPOs) and reduces data loss following unexpected disruptions. To get the most value from PITR, businesses need a solid understanding of how it works both on-premises and in public cloud environments.
Organizations running critical workloads on SQL Server, Oracle, or PostgreSQL can perform point-in-time backups and restores using native database tools. While each engine handles logs differently, the general point-in-time database model remains consistent—combining a full backup with incremental transaction logs.
For example:
In on-premises setups, it’s crucial to ensure that all transaction logs are complete and continuously archived. Missing logs or incorrect retention policies can result in recovery failures or inconsistent data. Regular testing of point-in-time backup and restore workflows should be part of every disaster recovery plan.
Managed database services simplify operations by automating backups and versioning, but administrators still need to understand each provider’s configuration limits and recovery options.
These cloud SQL point-in-time recovery and RDS point-in-time restore features offer convenience and lower administrative overhead, but flexibility is constrained by provider settings and retention policies. This can be a challenge for enterprises with strict compliance or long-term retention needs.
Cloud-native PITR features are simple to use and deploy quickly, but they can fall short when businesses require consistent protection across platforms, long retention periods, or data mobility between sites.
Enterprise-grade backup appliances, such as those from StoneFly, extend point-in-time recovery across multiple environments. They centralize data protection policies, ensure immutability, and use deduplication to optimize storage. These appliances work seamlessly with both on-prem and cloud point-in-time architectures, creating a cohesive recovery framework.
By integrating enterprise-grade solutions, organizations can standardize recovery point objectives, meet compliance requirements, and retain full control over their data. While built-in cloud SQL point-in-time recovery options are convenient, pairing them with an enterprise-class backup solution ensures critical data remains accessible, consistent, and protected—wherever it resides.
Implementing point-in-time restore across on-premises and cloud environments is not just a technical step but a key component of data resilience. Combining native tools with enterprise backup appliances allows businesses to maintain operational continuity and safeguard vital databases against both internal mishaps and external threats.
Data integrity and availability remain top priorities for enterprise IT teams. When systems fail, the speed and accuracy of data recovery determine how long critical workloads stay offline and how much information may be lost. This balance is where Recovery Point Objective (RPO) and Point-in-Time Recovery (PITR) work together.
The Recovery Point Objective (RPO) specifies the maximum amount of data an organization can afford to lose during an outage. It’s a time-based measure—expressed in minutes, hours, or days—indicating the longest acceptable gap between the most recent backup and a potential incident. For instance, an RPO of 15 minutes means the organization should never lose more than 15 minutes of data.
RPOs are defined through business impact analysis. Systems that handle financial transactions, healthcare information, or production data typically require extremely tight RPOs, sometimes measured in seconds, because any data loss could have costly or regulatory consequences.
In comparison, non-critical systems such as test environments or reporting databases can manage with less aggressive RPOs. Stricter RPO objectives demand more frequent point-in-time backups, which increases both storage use and management complexity.
While RPO focuses on how much data can be lost, the Recovery Time Objective (RTO) determines how quickly systems must be brought back online after a disruption. Together, they outline the broader disaster recovery plan—RPO drives backup frequency, while RTO dictates how efficiently operations resume.
– RPO = “How much data can we lose?”
– RTO = “How long can we be offline?”
Balancing RPO and RTO often comes down to finding the right mix of cost, performance, and complexity. Cloud-enabled infrastructures, for example, offer automation and replication capabilities that can lower both metrics, but they require thoughtful planning for data synchronization, bandwidth use, and storage tiering.
Point-in-Time Recovery (PITR) allows organizations to restore data to a specific moment before corruption, accidental deletion, or a cyber incident occurred. This capability makes it easier to achieve tighter RPO goals by enabling recovery to precise data states—sometimes even to the exact second.
With solutions like cloud SQL Point-in-Time Recovery or RDS Point-in-Time Restore, administrators can roll back a database to a chosen timestamp without performing a full system restore. This precision is especially valuable for transactional systems where even minor data loss can lead to lost orders or compliance issues.
An effective PITR strategy involves:
Point-in-time recovery is more than a technical function—it’s an essential safeguard that supports defined RPO goals and keeps business operations resilient.
Enterprise IT teams often need the flexibility to restore essential databases to a specific moment to correct user errors, data corruption, or unauthorized changes. Setting up Point‑in‑Time Recovery (PITR) across environments such as Cloud SQL, RDS, and on‑premises systems requires careful planning, configuration, and monitoring. The following guide outlines the technical details organizations should review before enabling and managing point‑in‑time database recovery.
Before turning on point‑in‑time restore, administrators should verify that the necessary infrastructure and identity permissions are in place. In cloud platforms like AWS RDS or Google Cloud SQL, PITR depends on automated backups and binary log generation.
Database configuration plays a central role in enabling point‑in‑time recovery. The framework relies on continuous log sequencing, often referred to as redo or transaction logs, which record each committed operation.
Log file sizes should be set according to expected transaction volume. Systems handling heavy workloads may need more frequent log switches and larger redo buffers to maintain performance. When implementing point‑in‑time architecture, keep redo logs separate from primary data files so that log‑intensive operations do not affect data storage throughput.
For managed databases, the length of binary log retention directly affects how far back a database can be restored. Defining a practical recovery point objective (RPO) helps balance resilience and cost—shorter retention reduces expense but narrows the recovery window, while longer retention increases flexibility at the expense of added storage.
Selecting the right point‑in‑time recovery architecture requires understanding how storage usage, backup frequency, and log retention influence cost and performance.
A balanced cost and retention plan allows the system to meet its recovery point objective while keeping resources under control.
Once point‑in‑time recovery is configured, continuous validation and monitoring help maintain reliability.
Consistent monitoring keeps point‑in‑time restore operations dependable and aligned with enterprise governance standards. In multi‑cloud or hybrid environments, synchronize PITR verification with broader integration and deployment schedules to ensure uniform data protection.
By following these configuration and management practices, organizations can establish reliable and predictable point‑in‑time recovery processes across platforms—strengthening resilience and minimizing data loss.
Building a recovery framework that meets enterprise standards goes beyond efficient data restoration. It requires that every point-in-time backup, transaction log, and restore procedure comply with security and regulatory requirements such as GDPR, HIPAA, and other data protection mandates. A point-in-time recovery not only protects business operations but also demonstrates an organization’s commitment to governance and regulatory consistency.
Regulations like GDPR and HIPAA obligate organizations to ensure the integrity, confidentiality, and availability of sensitive information. Point-in-time backup functions directly support these expectations by preserving immutable data snapshots within defined recovery point objectives. These verified backups can be presented during audits or data protection assessments as evidence of compliance.
In healthcare, where HIPAA rules apply, audit readiness demands the ability to trace records to their exact version before or after a modification or breach. A point-in-time restore allows IT teams to roll a database back to a specific moment without affecting unrelated data, maintaining compliance with the “minimum necessary” access and retention standards. Under GDPR, organizations must verify that any restored dataset remains lawfully processed, which is achieved when point-in-time recovery activities are securely logged, encrypted, and documented.
Cloud services such as cloud SQL point-in-time recovery or RDS point-in-time restore offer the flexibility to configure controls that meet these requirements. Administrators can define secure parameters for backup retention, replication zones, and encryption management throughout the lifecycle of each snapshot.
A compliant recovery design involves more than simply keeping copies of data—it requires strict access management and encryption at every level. Organizations should implement end-to-end encryption for both data at rest and in transit, including backup files, transaction logs, and metadata tied to point-in-time database operations. Using customer-managed keys ensures encryption keys stay under the organization’s control rather than solely with a cloud provider.
During restore-to-point-in-time processes, access must be enforced through role-based access control (RBAC) policies. Only authorized personnel—typically database administrators or compliance officers—should have permissions to perform restores or verify restored instances. These measures prevent unintended changes and meet segregation-of-duties requirements outlined by internal or external audits.
A well-structured point-in-time architecture should also track changes to credentials, encryption key rotations, and restore activities. Maintaining immutable logs of who initiated each restore, when it occurred, and which datasets were involved helps establish a verifiable chain of custody, strengthening both data integrity and accountability.
Every restore, modification, or recovery event should be part of a broader documentation process. Automated reporting built into enterprise backup platforms—on-premises or cloud-based—can capture metadata related to point-in-time recovery operations. These records may include timestamps, user IDs, encryption details, and validation checksums.
Such audit logs are essential for proving compliance and offer insights into the effectiveness of recovery processes against defined recovery point objectives. When these records align with corporate data policies, teams can validate that real-world recovery outcomes match policy expectations.
By integrating encryption, RBAC enforcement, point-in-time backup verification, and audit logging into recovery operations, organizations create a framework where data protection and compliance function as a unified system. Together, security, compliance, and point-in-time restore capabilities form a dependable architecture that supports business continuity while maintaining strong governance controls.
Creating a reliable backup and recovery plan involves more than keeping periodic data copies. It requires a structured process that combines full, differential, and point-in-time backups to reduce downtime and meet organizational Recovery Point Objectives (RPOs). A well-planned Point-in-Time Recovery (PITR) strategy enables IT teams to restore operations to a specific point before a disruption—whether caused by human error, a security incident, or a system failure.
A solid backup strategy blends multiple backup types according to data importance and system dependencies. Full backups provide the foundation by capturing the entire dataset. Differential backups record incremental changes since the last full backup, reducing both storage and recovery time. Point-in-time backups extend protection further by saving the exact state of data at defined moments, allowing recovery with minimal data loss.
For mission-critical databases and applications—such as RDS Point-in-Time Restore and Cloud SQL Point-in-Time Recovery—automation enhances accuracy and consistency. Storing backups in geographically separate or multi-tier cloud storage environments improves resilience and helps meet compliance standards for data durability.
A backup only proves its value when it can be successfully restored. Regular recovery drills validate not just the backup files but also the process of restoring them. Plan controlled failover tests during maintenance periods to avoid impacting production. During each test, confirm that point-in-time database integrity remains intact and that recovery can occur at the exact timestamps defined in the point-in-time setup.
Validation should also test access controls, encryption key restoration, and version consistency across systems. Recording results from these exercises builds confidence in your disaster recovery readiness and helps refine future responses.
The frequency of point-in-time backups should match business risk tolerance and defined RPOs. For systems that handle continuous transactions—such as ERP databases or online platforms—frequent point-in-time snapshots help limit data loss during outages or corruption. Aligning PITR intervals with the RPO ensures rollbacks, whether just a few minutes or an hour before the failure, restore data to a usable and compliant state.
Automated orchestration tools can adjust backup intervals based on workload activity and service-level requirements. This flexibility helps optimize storage use while maintaining strict recovery timelines. Understanding the operational meaning of point-in-time recovery—returning systems to the exact moment before an issue occurred—helps justify scheduling and resource allocation during planning discussions.
A recovery plan succeeds only when everyone understands and follows it. IT teams should maintain clear runbooks that outline what point-in-time restore is, how to perform it, and what verification steps follow. Sharing this plan during regular IT governance meetings promotes accountability and ensures all departments are prepared.
Documentation must remain current and accessible. Include detailed procedures for point-in-time restore execution, escalation paths for incident handling, and post-recovery checks. Engaging both infrastructure and application teams ensures the plan reflects real-world system behavior, not just written policy.
A well-executed Point-in-Time Recovery strategy turns data protection from a routine task into a critical element of business resilience. With consistent backup practices, thorough testing, and clear communication, organizations can restore operations to any specific moment with confidence and reliability.
As enterprise data environments continue to expand across hybrid and multi-cloud infrastructures, protecting critical information requires more than traditional backup routines. Point-in-Time Recovery (PITR) provides the precision and flexibility organizations need to safeguard transactions, maintain data integrity, and minimize operational disruption. By enabling administrators to restore systems to the exact moment before an error, corruption event, or cyber incident occurred, PITR significantly reduces the risk of costly data loss.
When integrated into a broader data protection strategy—alongside clear RPO and RTO targets, automated backups, strong security controls, and regular recovery testing—point-in-time recovery becomes a powerful pillar of enterprise resilience. Whether implemented through native database capabilities or supported by enterprise-grade backup platforms, PITR allows organizations to maintain continuous operations while meeting regulatory and compliance requirements.
A well-designed point-in-time recovery framework transforms backup from a reactive safeguard into a proactive strategy for business continuity. As threats such as ransomware, accidental data deletion, and system failures grow more frequent, enterprises that invest in precise recovery capabilities will be far better prepared to protect their data, maintain service reliability, and recover quickly from unexpected disruptions.













Join our mailing list to receive the latest news, updates, and promotions from StoneFly.