Two categories of organizations get data retention wrong in opposite directions. The first keeps everything indefinitely — no deletion schedules, no tiering policies, no documented rationale — because storage is cheap and deletion feels risky. The second deletes aggressively to reduce storage costs, without a legal hold process or audit trail, and discovers the gap when litigation requires documents that no longer exist. Neither approach is a data retention strategy. Both create legal and financial exposure that a properly designed retention policy would have prevented.
Data retention is not purely a compliance function, though compliance drives most of the deadlines. It is an intersection of legal obligation, operational necessity, storage economics, and risk management. The right data retention policy keeps data as long as it must be kept — by law, by contract, or by business need — archives it to cost-appropriate storage as it ages, and deletes it on a defensible schedule when the retention period expires. Done well, it reduces storage costs by eliminating data that serves no purpose, reduces legal risk by ensuring defensible deletion practices, and satisfies auditors with documented, automated evidence of compliance.
This blog covers data retention best practices across policy design, data lifecycle management, regulatory compliance requirements, archiving strategy, and data integrity — the full scope of what enterprise data governance requires from a retention program.
A data retention policy is a formal document that defines which data the organization retains, for how long, in what storage format, and under what deletion schedule. It maps data categories — financial records, employee data, customer records, contracts, system logs, email communications — to retention periods derived from legal requirements, regulatory mandates, contractual obligations, and business judgment. It also defines the process for legal holds (suspending normal deletion schedules when data may be relevant to litigation or investigation), and the method for documenting that deletion occurred on schedule.
A complete data retention policy covers four elements that many organizations omit from their initial versions. First, scope: which data types and systems are in scope, explicitly including cloud storage, endpoint devices, SaaS applications, and backup copies — not just primary databases and file shares. Second, legal hold procedures: who can place a hold, how holds are tracked, and how they are lifted when the triggering matter resolves. Third, deletion verification: how the organization confirms that data was actually deleted at the end of its retention period, not merely flagged for deletion in a system that never executed the deletion. Fourth, policy review cadence: how often the policy is reviewed against changes in regulatory requirements, and who is responsible for keeping it current.
The most common gap in enterprise data retention policies is that they document retention requirements but do not automate enforcement. A policy that says “financial records are retained for 7 years” is unenforceable without a records management system that actually applies that rule, flags records approaching end-of-retention, and executes deletion with an audit trail. Policy without enforcement is documentation; enforcement is what makes it a data retention management program.
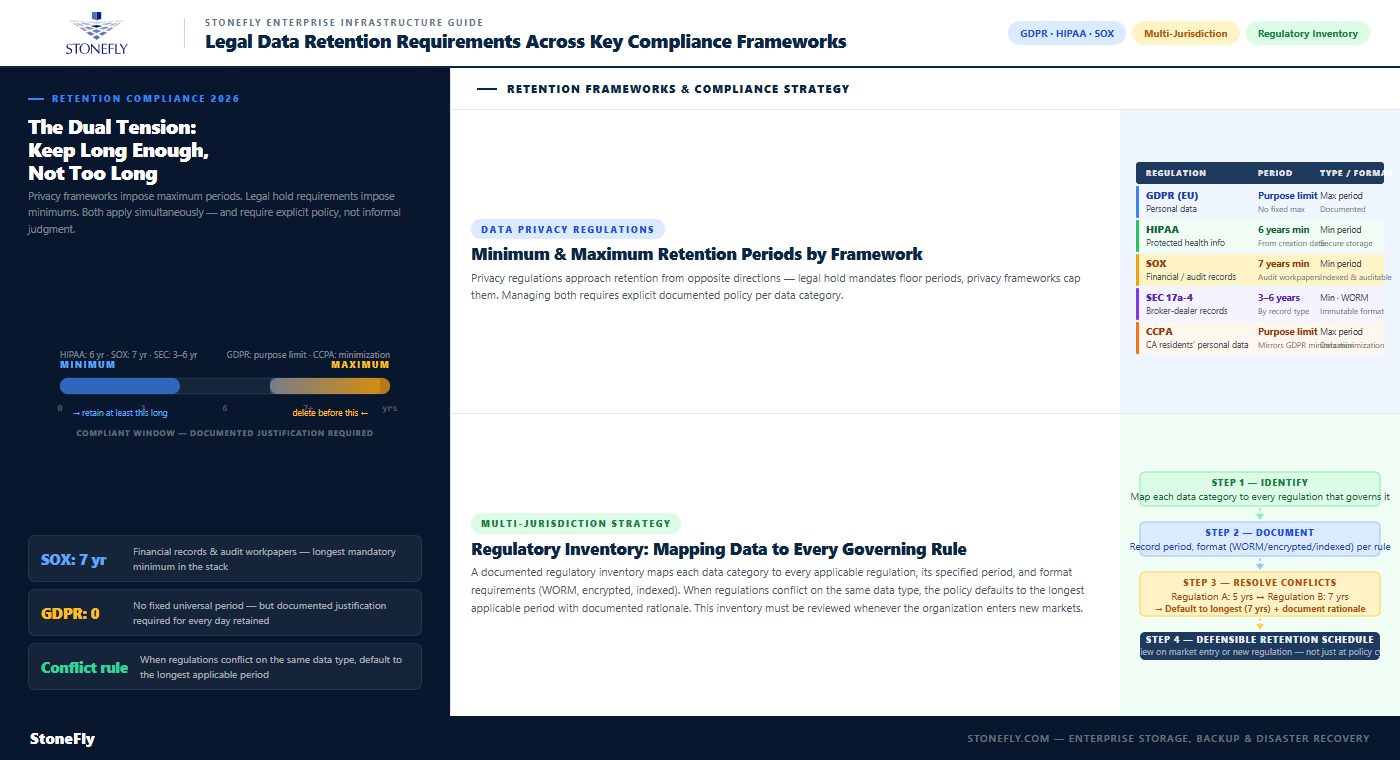
Data privacy regulations impose retention requirements from two directions: minimum periods (data must be kept for at least X years to satisfy audit or legal requirements) and maximum periods (data must not be kept longer than necessary for the purpose it was collected, under privacy frameworks like GDPR). Managing both simultaneously — keeping data long enough to satisfy legal hold requirements while not keeping it longer than privacy regulations permit — is the central tension of data retention compliance, and it requires explicit policy rules rather than informal judgment.
Key data protection regulations that define retention obligations include GDPR (EU), which requires that personal data not be retained longer than necessary for its original purpose, with no fixed universal period but a requirement for documented justification of any retention period; HIPAA, which mandates a minimum 6-year retention period for protected health information and related documentation; SOX (Sarbanes-Oxley), which requires 7 years for financial records and audit workpapers; and CCPA and its amendments, which mirror GDPR’s data minimization principle for California residents’ personal data. SEC Rule 17a-4 requires broker-dealer records to be retained in WORM format for periods ranging from 3 to 6 years depending on record type.
Legal data retention requirements vary not just by regulation but by jurisdiction and industry sector, creating a compliance matrix that multi-national enterprises must navigate carefully. A pharmaceutical company operating in the US, EU, and Japan simultaneously faces FDA 21 CFR Part 11 requirements (electronic records and signatures), EU GMP Annex 11 requirements, and Japanese PMDA requirements — each with different retention periods, format requirements, and audit trail specifications for clinical and manufacturing records. A financial institution faces FINRA, SEC, OCC, and state-level requirements that may differ on retention periods for the same record type.
Records retention compliance in complex environments requires a regulatory inventory — a documented mapping of each data category to every regulation that governs it, the retention period each regulation specifies, and the format requirements (WORM, encrypted, indexed, etc.) each imposes. Where regulations conflict — one requiring 5 years and another requiring 7 years for the same data type — the policy should default to the longest applicable period, with a documented rationale. This regulatory inventory is the foundation on which defensible retention schedules are built, and it must be reviewed whenever the organization enters new markets or new regulations take effect.
| Regulation | Sector | Key Data Type | Minimum Retention Period | Format Requirement |
| HIPAA | Healthcare | Protected health information (PHI) | 6 years from creation or last effective date | Secure, access-controlled; WORM recommended |
| SOX | Public companies | Financial records, audit workpapers | 7 years | Indexed, retrievable, tamper-evident |
| SEC Rule 17a-4 | Financial services | Broker-dealer communications and records | 3–6 years (type-dependent) | WORM storage, accessible to regulators |
| GDPR | Any org handling EU personal data | Personal data of EU residents | No fixed minimum; no longer than necessary | Documented purpose; data minimization required |
| FDA 21 CFR Part 11 | Pharma/biotech | Electronic records supporting submissions | 2 years post-approval (or per applicable regulation) | Audit trail, electronic signatures, access controls |
| FINRA Rule 4511 | Broker-dealers | Books and records | 6 years (general); 3 years easily accessible | WORM; duplicate offsite copy required |
| CCPA/CPRA | Orgs with CA consumer data | California consumer personal information | No fixed minimum; purpose limitation applies | Documented retention justification required |
Data lifecycle management (DLM) is the process of managing data from creation or ingestion through active use, archiving, and eventual deletion, with defined policies governing how data moves between storage tiers and what happens to it at each stage. A data retention policy defines the rules; data lifecycle management is the operational framework that enforces them automatically as data ages.
Enterprise data moves through predictable stages after it is created: active use (frequently accessed, on high-performance primary storage), warm (occasionally accessed, appropriate for lower-cost secondary storage), cold (rarely accessed, subject to long-term retention requirements, appropriate for archival storage), and deleted (retention period has expired, data is permanently removed with an audit trail). Data lifecycle policies automate the transitions between these stages based on age, access frequency, and data classification — without manual intervention from storage administrators.
The business case for automated lifecycle management is straightforward: primary storage — NVMe SSDs, all-flash arrays — is expensive on a per-terabyte basis. Data that is 3 years old and has not been accessed in 18 months should not be on primary storage. Automated tiering moves that data to cold storage or object storage at a fraction of the cost, freeing primary storage capacity for current workloads. A well-implemented data lifecycle management program reduces primary storage consumption by 30–50% in environments with significant data accumulation over time, while keeping the data accessible for compliance and legal hold purposes.
Retention risk management addresses a liability that is less intuitive than the risk of deleting data too early: the risk of keeping data longer than required. Over-retention creates legal exposure because any data the organization holds at the time of litigation is subject to discovery. Data retained past its legal hold obligation that contains damaging communications, incomplete records, or inconsistent information can significantly increase litigation costs and outcomes. The principle of defensible deletion — deleting data on a documented, consistently enforced schedule — is the legal protection that over-retention eliminates.
Over-retention also creates data breach risk. Data that should have been deleted but was not is data that can be compromised in a breach event. A data breach that exposes customer personal data that should have been deleted three years earlier carries regulatory exposure under GDPR, CCPA, and similar frameworks beyond the breach itself — the organization must explain why the data was retained past its stated purpose. Retention risk management treats expired data not as an asset to be preserved but as a liability to be disposed of on schedule, with documented evidence of disposal.
Long-term data storage solutions for compliance and archiving workloads must satisfy requirements that differ from production storage: they need to be low-cost per terabyte, highly durable over multi-year periods, capable of enforcing immutability (WORM) for regulations that require it, and indexable for legal hold and e-discovery retrieval. Cold storage solutions — object storage with infrequent-access tiers, tape-based archival systems, and object storage platforms with S3-compatible APIs — meet these requirements at a fraction of the cost of primary storage.
Data archiving solutions move data from active primary storage to archival tiers based on lifecycle policy triggers: age thresholds, last-access dates, file type classifications, or explicit archival actions from records management systems. The archived data remains accessible — a legal hold search can retrieve a 7-year-old email from the archive — but it no longer consumes expensive primary storage capacity. For organizations subject to SEC Rule 17a-4 or FINRA’s WORM requirements, the archival target must specifically support non-rewritable, non-erasable storage — a technical requirement that standard NAS or block storage does not satisfy without WORM policy enforcement at the object or file system level.
Data storage optimization through lifecycle automation is the operational mechanism that converts a data retention policy from a document into a cost management tool. Storage tiering — automatically moving data between high-performance primary storage, lower-cost capacity storage, and archival cold storage — eliminates the manual storage management burden while enforcing the lifecycle policies the retention program requires. The cost differential between tiers is significant: NVMe primary storage costs $0.10–0.30 per GB per month in enterprise environments; cold object storage costs $0.004–0.023 per GB per month. For petabyte-scale environments with years of accumulated data, the savings from correct tiering represent millions of dollars annually.
Effective data storage optimization requires accurate data classification at the point of ingestion — knowing what a piece of data is, what retention period applies to it, and what storage tier is appropriate at each lifecycle stage — before the data is stored, not after. Retroactive classification of large existing datasets is expensive and error-prone. Organizations that build classification into their data handling procedures from the start, applying metadata tags and retention labels at creation, have a significantly easier time implementing automated lifecycle policies than those attempting to classify accumulated unstructured data.
Enterprise data governance provides the organizational structure — roles, responsibilities, and decision-making authority — that keeps the data retention program operational over time. An information governance strategy for data retention defines who owns the retention policy (typically Legal or Compliance, with IT owning the technical implementation), who approves changes to retention schedules, who manages legal holds, and who is accountable for ensuring that automated lifecycle policies are running correctly and producing audit-ready evidence of compliance.
Without governance, data retention programs decay: retention schedules go unreviewed as regulations change, legal hold procedures are not followed consistently, and the technical enforcement mechanisms drift out of alignment with the documented policy. Data governance frameworks — whether implemented through a formal Data Governance Council, through a records management officer function, or through integrated GRC (Governance, Risk, and Compliance) platforms — provide the institutional structure that keeps the retention program current and enforceable.
Data compliance frameworks for retention — COBIT, ISO 27001, NIST SP 800-53, and industry-specific frameworks like HITRUST for healthcare — provide structured approaches to implementing and auditing data retention controls. These frameworks define the control objectives (what the retention program must accomplish), the control activities (what specific processes and technical measures are required), and the evidence requirements (what documentation auditors will request to verify controls are operating effectively).
Compliance data management platforms — tools including Varonis, BigID, OneTrust, and Microsoft Purview — automate much of the data discovery, classification, and retention enforcement that manual data retention programs struggle to scale. They scan the environment for data subject to retention requirements, classify it according to defined policies, apply retention labels, track legal holds, and generate audit reports documenting that retention and deletion activities occurred on schedule. For enterprises managing data subject to multiple overlapping compliance frameworks simultaneously, automated compliance data management is the difference between a sustainable program and one that requires disproportionate manual effort to maintain.
Data integrity management for retained data addresses a problem that does not exist for active data: media degradation and format obsolescence over multi-year storage periods. Data retained for 7, 10, or 25 years may outlive the storage media it was written to, the file format it was stored in, and the application that originally created it. Data integrity assurance for long-term retained data requires periodic integrity verification (checksums validated against stored values to detect silent data corruption), media refresh cycles (migrating data to new storage media before the existing media reaches end-of-life), and format migration (converting data from obsolete formats to currently readable ones before the originating application is decommissioned).
Object storage platforms with built-in integrity verification — comparing stored checksums against data on read and triggering repairs from redundant copies when discrepancies are detected — provide the strongest data integrity assurance for long-term archival data. This is a meaningful distinction from traditional file storage, which typically does not perform read-time integrity verification. For compliance data that must be produced in a legal or regulatory proceeding years after it was stored, the ability to demonstrate that the retrieved data is identical to what was originally archived — byte-for-byte, verified by cryptographic hash — is the foundation of defensible records management.
Data loss prevention (DLP) strategies for retained data address both accidental and malicious data loss from the archives that contain an organization’s compliance-critical records. Accidental deletion — an administrator executing a bulk delete against the wrong storage bucket, or a misconfigured lifecycle policy deleting data before its retention period expires — is the most common form of retained data loss in enterprise environments. DLP controls for retention include: immutable storage policies that prevent deletion during the retention period regardless of credentials; soft-delete mechanisms that retain deleted data in a recoverable state for a defined recovery window; and access controls that limit who can modify or delete archived data to a small, audited set of authorized users.
Data handling procedures for retained and archived data should specify access controls, encryption requirements (encryption at rest and in transit is mandatory for data subject to HIPAA, PCI DSS, and most privacy regulations), and the chain-of-custody documentation required when archived data is retrieved for legal hold or e-discovery. Data breach prevention for archived data requires the same controls applied to active data — encryption, access logging, network isolation — because archived compliance data frequently contains exactly the categories of sensitive information (PHI, financial records, personal data) that breach notification laws are designed to protect.
Scalable storage solutions for enterprise data retention must handle three requirements simultaneously: capacity growth over multi-year periods without forklift upgrades, performance sufficient for legal hold and e-discovery retrieval without a dedicated search appliance, and cost efficiency appropriate to the infrequent-access nature of archival data. Object storage — storage that manages data as objects with metadata, accessible via S3-compatible REST APIs — has become the dominant architecture for long-term data retention because it satisfies all three requirements at scale.
Object storage scales horizontally: capacity is added by adding nodes to the cluster, with data automatically rebalanced across the expanded pool. There is no practical limit to the scale of an object storage cluster — petabyte-scale deployments are standard in enterprise archiving environments. Metadata-rich object storage makes retained data searchable without a separate indexing layer: retention labels, creation dates, data classifications, and legal hold flags are stored as object metadata and queryable directly. And object storage economics — particularly on-premises object storage where the CapEx is amortized over multiple years — produce per-terabyte costs far below primary storage, making it appropriate for the large, slowly-growing datasets that long-term retention programs accumulate.
The storage platform underneath a data retention program determines whether the program’s policy commitments — specific retention periods, WORM enforcement, e-discovery retrieval, tiered lifecycle management — can actually be executed at the scale and cost the business requires. StoneFly’s storage platforms are designed for exactly this workload profile: high-capacity, long-duration, compliance-grade data retention with the access patterns and integrity requirements that enterprise archiving demands.
StoneFly’s USO (Unified Scale-Out SAN, NAS, and S3 Object Storage) provides the S3-compatible object storage target that enterprise data retention and archiving programs require. The USO delivers an on-premises S3 endpoint that accepts data from backup tools, content management platforms, records management systems, and data archiving solutions via standard S3 API — eliminating the egress costs and data gravity issues of cloud-based object storage for large retained datasets. For organizations subject to SEC Rule 17a-4, FINRA, or HIPAA WORM requirements, the USO supports object lock policies that enforce non-rewritable, non-erasable retention at the object level for defined periods, satisfying the WORM format requirements of regulatory frameworks without separate compliance storage hardware.
StoneFly’s SCVM (Software-Defined Storage Virtual Appliance) delivers automated storage tiering across performance, capacity, and archive tiers — the technical mechanism that converts a data lifecycle management policy into automatic storage optimization. As data ages past defined thresholds, SCVM migrates it from NVMe primary storage to lower-cost capacity tiers or to the USO object storage archive, without manual intervention and without disrupting application access to the data. This automated tiering is what makes data storage optimization from lifecycle management a continuous operational outcome rather than a periodic project.
For organizations building a complete data retention architecture — active data on performance storage, aging data automatically tiered to the USO archive, compliance metadata and lifecycle policies enforced at the storage layer — StoneFly’s USO and SCVM provide the infrastructure foundation that makes retention policy enforcement technically scalable without adding proportional administrative overhead.
The organizations that get the most value from data retention programs are the ones that treat them as active management tools rather than passive compliance obligations. A well-designed data retention policy eliminates unnecessary storage costs by ensuring data is deleted when it no longer needs to be kept. It reduces litigation risk by creating defensible deletion records. It reduces breach exposure by ensuring that sensitive data is not retained past its useful life. And it satisfies auditors with documented, automated evidence of compliance rather than manual attestations that are expensive to produce and difficult to defend.
Building that program requires four things working together: a data retention policy with documented retention schedules derived from regulatory requirements, not arbitrary decisions; data lifecycle management automation that enforces those schedules without manual intervention; scalable storage infrastructure that tiers data to cost-appropriate storage as it ages; and data integrity and governance controls that keep retained data trustworthy and the program auditable over time. Each element depends on the others — a policy without enforcement is documentation; infrastructure without policy is unmanaged storage; governance without automation is a program that cannot scale.
Contact StoneFly to discuss how USO and SCVM can serve as the storage foundation for your enterprise data retention, archiving, and lifecycle management program.








Join our mailing list to receive the latest news, updates, and promotions from StoneFly.