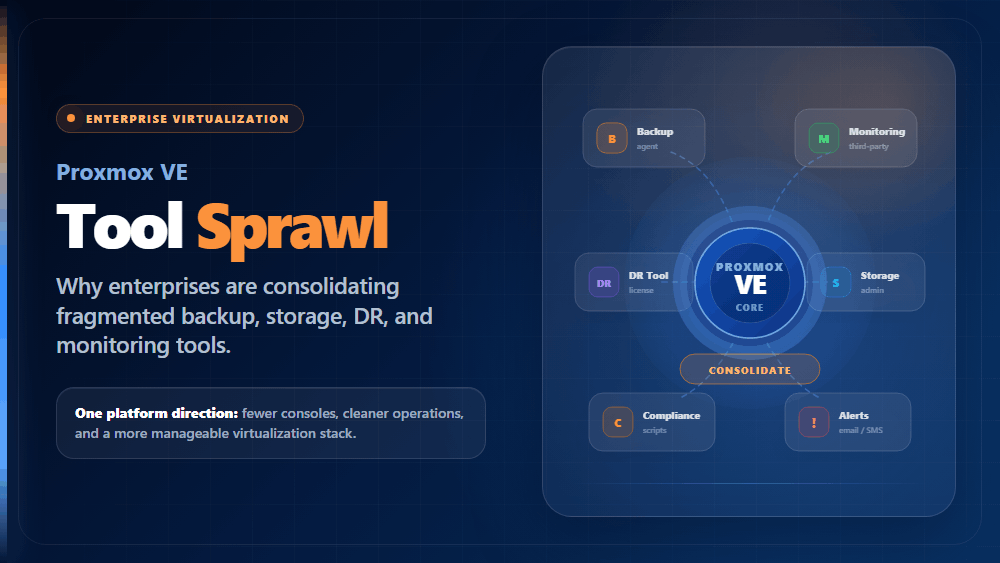
By 2026, the amount of data stored in cloud environments alone is projected to exceed 200 zettabytes globally. More than 63 percent of enterprises already manage over 100 terabytes of active data, and AI workloads, analytics pipelines, and real-time applications are accelerating that growth with no ceiling in sight. Centralized storage architectures — a single storage array or a single data center handling all of an organization’s data — simply cannot scale to meet these demands without becoming the bottleneck that limits everything above them.
Distributed data storage answers this by replacing the single storage point with a coordinated network of storage nodes that collectively handle capacity, performance, and redundancy. Data is partitioned, replicated, and managed across multiple physical or virtual locations — so no single node failure takes down the system, no single location limits scale, and no single access point creates a throughput ceiling.
This guide covers what distributed data storage is, how distributed storage systems work, the four main types of distributed storage architecture, leading distributed file system and object storage implementations, high availability and disaster recovery design, and how enterprise IT teams deploy distributed storage at scale.
Distributed data storage is a storage architecture in which data is stored across multiple interconnected nodes — physical servers, virtual machines, or cloud instances — rather than on a single centralized system. Each node holds a portion of the total data, and the distributed storage system coordinates access, replication, and consistency across all nodes so that the storage appears unified to applications and users.
The core purpose of distributed data storage is to eliminate the constraints of centralized storage: a single point of failure that can take down the entire storage environment, a fixed capacity ceiling that requires disruptive upgrades, and a single access point that becomes a throughput bottleneck at scale. Distributed storage systems address all three by spreading both data and the work of serving it across many nodes simultaneously.
What constitutes a distributed data storage system varies in architecture and protocol. Distributed file systems expose storage as a shared file namespace. Distributed object storage exposes data through REST APIs. Distributed block storage presents raw block volumes to servers. Distributed database systems manage structured data with distributed query execution. Each type shares the same foundational principle — data across many nodes, managed as one — but they optimize for different workloads and access patterns.
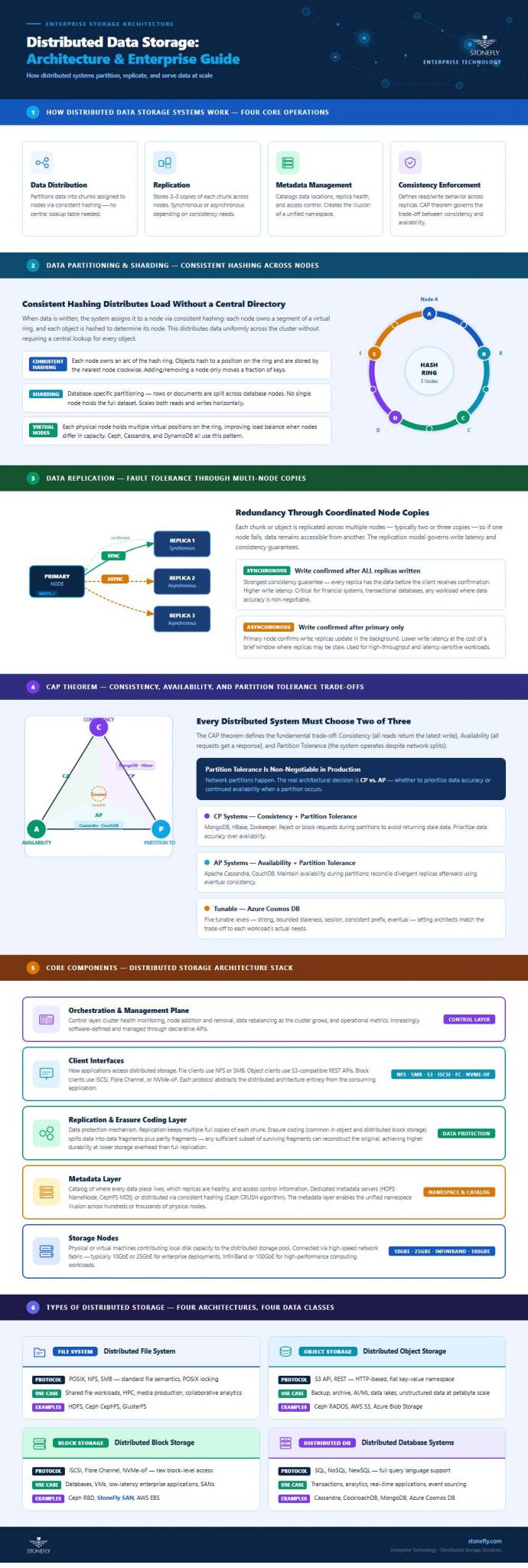
The internal mechanics of distributed data storage systems share a common set of operations regardless of the specific type: data distribution, replication, metadata management, and consistency enforcement.
When data is written to a distributed storage system, it is partitioned — divided into chunks or shards — and assigned to storage nodes according to a distribution algorithm. Consistent hashing is the most common method: each node is assigned a range of the hash space, and each data object is hashed to determine which node stores it. This distributes data uniformly without requiring a central lookup table for every object. Sharding is the database-specific term for the same concept: partitioning rows or documents across database nodes so no single node holds the full dataset.
Replication is what makes distributed data storage systems resilient. Each data chunk or object is replicated across multiple nodes — typically two or three copies — so that if one node fails, the data remains accessible from another. Replication can be synchronous (the write is only confirmed once all replicas are written, ensuring consistency) or asynchronous (the write is confirmed after the primary node writes, with replicas updated in the background, trading some consistency for lower write latency).
Modern distributed storage systems support both models and allow administrators to choose per-volume or per-bucket replication policies based on workload requirements.
Every distributed storage system maintains metadata — a catalog of where each piece of data lives, which nodes hold which replicas, the health state of each node, and access control information. In some architectures, metadata is managed by dedicated metadata servers (as in HDFS, which uses a NameNode). In others, metadata is itself distributed across the cluster using consistent hashing and peer-to-peer protocols (as in Ceph’s CRUSH algorithm). The metadata layer is critical: it is what allows the distributed storage system to present itself as a single unified storage namespace while data is physically spread across hundreds or thousands of nodes.
Every distributed data storage system must make a fundamental architectural trade-off defined by the CAP theorem: a distributed system can guarantee at most two of three properties — Consistency (all reads receive the most recent write), Availability (all requests receive a response, though not necessarily the most recent data), and Partition Tolerance (the system continues operating despite network partitions between nodes).
In practice, partition tolerance is non-negotiable for any production distributed system. The real choice is between consistency and availability during network events. CP-oriented distributed storage and database systems (MongoDB in default mode, HBase, Zookeeper) prioritize data accuracy — rejecting requests or blocking operations during partitions to avoid returning stale data. AP-oriented systems (Apache Cassandra, CouchDB) maintain availability during partitions and reconcile divergent replicas afterward using eventual consistency. Modern platforms like Azure Cosmos DB offer tunable consistency models — strong, bounded staleness, session, consistent prefix, eventual — allowing architects to select the appropriate trade-off per workload.
A distributed storage architecture consists of several interdependent layers that together deliver the appearance of unified storage across many nodes.
Distributed data storage encompasses four distinct system types, each optimized for a different data structure and access pattern. Understanding the differences is the starting point for any enterprise storage architecture decision.
| Type | Protocol | Primary Use Case | Examples |
| Distributed File System | POSIX, NFS, SMB | Shared file workloads, HPC, media | HDFS, Ceph CephFS, GlusterFS |
| Distributed Object Storage | S3 API, REST | Backup, archive, AI/ML data lakes | Ceph RADOS, AWS S3, Azure Blob |
| Distributed Block Storage | iSCSI, Fibre Channel, NVMe-oF | Databases, VMs, low-latency apps | Ceph RBD, StoneFly SAN, AWS EBS |
| Distributed Database Systems | SQL / NoSQL / NewSQL | Transactions, analytics, real-time | Cassandra, CockroachDB, MongoDB |
A distributed file system presents a shared, hierarchical file namespace accessible by multiple clients simultaneously. Files are stored as blocks distributed across storage nodes, but clients interact with them through familiar directory and file path semantics using standard protocols like NFS and SMB. Distributed file systems are the native storage layer for high-performance computing (HPC), shared media workflows, and enterprise file services.
The distributed file system storage mechanism involves breaking files into blocks, distributing those blocks across nodes according to a placement policy, and maintaining a namespace index that maps file paths to their block locations across the cluster.
Distributed object storage stores data as discrete objects — each with a unique identifier, the data payload itself, and a flexible metadata dictionary. Objects are accessed through REST APIs (most commonly the AWS S3 API, which has become the de facto standard for distributed object storage). There is no directory hierarchy; objects are addressed by bucket and key.
Distributed object storage is architected for massive scale — billions of objects, exabytes of capacity — at low cost. It is the storage architecture underlying cloud data lakes, AI training data repositories, backup and archive systems, media asset libraries, and log storage. The S3-compatible object storage API has become so dominant that on-premises distributed object storage systems, including Ceph and StoneFly’s S3 appliances, implement the same API to ensure application portability.
Distributed block storage presents raw block volumes to servers, which format those volumes with a local file system (NTFS, ext4, XFS) for structured application use. Block storage is the storage type used by databases, virtual machine disks, and any application that requires low latency, predictable IOPS, and direct I/O control.
In distributed architectures, block storage volumes are striped and replicated across storage nodes using protocols such as iSCSI (for Ethernet-based networks), Fibre Channel (for SAN fabrics), or NVMe-oF (for ultra-low latency NVMe access over Ethernet or InfiniBand). SAN storage arrays from StoneFly deliver distributed block storage for enterprise environments requiring sub-millisecond latency for database and virtual machine workloads.
Distributed database systems distribute both data storage and query execution across multiple nodes. Unlike file, object, and block storage which manage raw data, distributed database systems manage structured data with schema enforcement, transaction support, and query processing.
The distributed database architecture differs fundamentally from centralized databases: the query planner must decompose queries across data shards, coordinate transactions across nodes using distributed consensus protocols (Paxos or Raft), and maintain consistency guarantees defined by the CAP trade-off configured for the specific deployment. Apache Cassandra (AP, tunable consistency), CockroachDB (CP, global transactions), and MongoDB (configurable) represent the leading enterprise distributed database systems as of 2026.
Three distributed file systems dominate enterprise deployments, each with a distinct architecture and primary use case.
HDFS is the primary distributed file system storage mechanism for Apache Hadoop, designed to run on commodity hardware and store very large files (gigabytes to terabytes each) with high sequential throughput. The architecture is master-worker: a single NameNode manages the file namespace and metadata, while DataNodes store actual file blocks. Files are split into 128MB blocks by default, each replicated three times across different DataNodes and racks for fault tolerance.
HDFS optimizes for write-once, read-many access patterns — the canonical batch analytics workload. It delivers very high sequential read throughput from a distributed cluster and handles automatic DataNode failure recovery by re-replicating blocks from surviving copies.
Ceph is an open-source, software-defined distributed storage platform that delivers object, block, and file storage simultaneously from a single cluster. Its CRUSH (Controlled Replication Under Scalable Hashing) algorithm distributes data across nodes without a central metadata bottleneck, making Ceph one of the most scalable distributed storage architectures available. The Ceph v20.2.0 release (Tentacle, November 2025) added FastEC, delivering two to three times erasure coding performance improvements, and production-ready deployment via Cephadm.
Ceph integrates natively with OpenStack, Kubernetes, and VMware, making it the de facto distributed storage backend for many private cloud deployments. It supports object access via a fully S3-compatible gateway (RADOS Gateway), block access via Ceph RBD (RADOS Block Device), and file access via CephFS — all from the same underlying storage cluster.
GlusterFS is a distributed file system optimized specifically for file storage workloads, known for operational simplicity relative to Ceph. It uses a stackable translator architecture to add capabilities (replication, striping, geo-replication) as modules, and exposes data through NFS and SMB for broad client compatibility. GlusterFS is favored in environments where straightforward deployment and management of distributed file storage is the priority, and where the unified multi-protocol capability of Ceph is not required.
Distributed object storage has emerged as the dominant storage architecture for unstructured data at scale. The S3 API — introduced by AWS for Amazon S3 — has become the standard interface for distributed object storage globally. Object storage systems that implement the S3 API allow applications built for AWS S3 to connect to any S3-compatible storage without code changes, whether that storage runs in the public cloud or on-premises hardware.
The distributed object storage architecture uses erasure coding rather than full replication for data protection at scale. Instead of storing three full copies of every object, erasure coding splits each object into data fragments and parity fragments (for example, 4 data + 2 parity in a 4+2 configuration), distributing them across nodes. Any four of the six fragments can reconstruct the full object, meaning two simultaneous node failures can be tolerated with 1.5x storage overhead rather than the 3x overhead of triple replication.
Enterprise object storage deployments in 2026 are driven heavily by AI and ML workloads. Training datasets for large language models and computer vision systems can reach hundreds of terabytes to petabytes. Distributed object storage — with its scale-out capacity, parallel access, and S3 API compatibility with machine learning frameworks — is the architecture of choice for AI data infrastructure.
82 percent of organizations rely on hybrid cloud storage models, combining public cloud infrastructure with private on-premises storage. Distributed cloud storage — extending distributed storage principles across both environments — is the architecture that makes hybrid models operationally coherent rather than just two separate storage environments managed in parallel.
In a distributed cloud storage architecture, on-premises distributed storage systems and cloud object or block storage share a unified namespace, common API, and synchronized data. Enterprise cloud storage solutions bridge this gap through cloud tiering (automatically moving cold data from on-premises storage to cloud object storage based on access patterns), cloud caching (placing hot data close to the workloads that consume it while maintaining the authoritative copy in distributed cloud storage), and active-active replication (maintaining synchronized writable copies in both on-premises and cloud environments for workload mobility and resilience).
The shift toward S3-compatible object storage architecture as the universal data access layer enables this hybrid model. When on-premises distributed storage and cloud storage both expose the same S3 API, applications are storage-location-agnostic — the same code accesses on-premises distributed object storage and public cloud storage without modification.
High availability in distributed data storage is not an add-on feature — it is an architectural property that emerges from how data is distributed and replicated across nodes. When any single node fails, the distributed storage system continues serving requests from replicas held by surviving nodes, automatically detects the failure, and begins re-replicating data to restore the configured redundancy level.
Synchronous replication writes data to multiple nodes simultaneously and confirms the write only after all designated replicas have acknowledged. This guarantees zero data loss on node failure — the confirmed write is always present on at least two nodes — but adds write latency equal to the round-trip time to the slowest replica. Synchronous replication is appropriate for databases, financial transaction logs, and any workload where data loss on failure is unacceptable.
Asynchronous replication confirms writes after the primary node acknowledges, with replica updates propagating in the background. Write latency is lower because the application does not wait for remote replicas. The trade-off is a replication lag window during which a primary node failure could result in the loss of recently written data not yet propagated to replicas. Asynchronous replication is appropriate for backup data, analytics workloads, and geo-replication across WAN links where synchronous replication latency would be prohibitive.
Erasure coding provides fault tolerance with lower storage overhead than full replication. A common enterprise configuration is 8+3 erasure coding: each object is split into 8 data fragments and 3 parity fragments, distributed across 11 nodes. Any 8 of the 11 fragments can reconstruct the original object, tolerating simultaneous failure of any 3 nodes. The storage overhead is 11/8 = 1.375x, compared to 3x for triple replication. Erasure coding is standard in distributed object storage deployments where capacity efficiency at petabyte scale matters more than the slightly higher reconstruction overhead on reads.
High availability distributed storage systems use distributed consensus protocols — Paxos or Raft — to coordinate decisions across nodes without a single coordinator that becomes a point of failure. Raft is now the more widely implemented of the two (used by etcd, CockroachDB, and many modern distributed systems) due to its cleaner understandability. The consensus protocol ensures that even during node failures or network partitions, the cluster agrees on which node is the current leader, which writes have been committed, and how to proceed — maintaining consistency without requiring a centralized arbiter.
Distributed data storage architecture provides the foundation for disaster recovery, but DR strategy requires deliberate design beyond what replication alone delivers.
Geographic distribution is the first layer. A distributed storage cluster in a single data center can survive individual node and rack failures, but a facility-level event (power loss, fire, natural disaster) can take down the entire cluster. Geo-distributed distributed data storage — with cluster nodes across multiple physical sites or cloud availability zones, replicating data across locations — eliminates the single-site failure scenario. Most enterprise distributed storage solutions support synchronous geo-replication within a metropolitan region (where latency allows) and asynchronous replication across greater distances.
Recovery Point Objective (RPO) in distributed storage is determined by the replication mode and frequency. Synchronous replication delivers RPO of zero — no data loss on failure because every confirmed write is already present on geographically separated replicas. Asynchronous replication delivers RPO equal to the replication lag — typically seconds to minutes for local WAN links, potentially longer for intercontinental replication.
Recovery Time Objective (RTO) in distributed storage is typically very low compared to traditional backup-and-restore DR, because the data is already present on surviving nodes. Failover in a geo-distributed cluster is a metadata operation — redirecting clients to surviving nodes that already hold the data — rather than a data movement operation. Production enterprise distributed storage solutions can achieve RTOs measured in seconds for automatic failover, assuming the network and client configuration supports rapid path switching.
Immutable backup integration extends disaster recovery storage solutions beyond what replication alone provides. Replication propagates writes — including ransomware encryption events — across all replicas. An immutable, air-gapped backup repository that is not part of the live distributed storage cluster provides a clean recovery point that ransomware cannot corrupt, complementing the high availability that replication delivers within the production distributed storage environment.
Storage resource management in distributed data storage systems encompasses capacity planning, performance monitoring, tiering, and policy enforcement across a pool of nodes that changes dynamically as nodes are added, replaced, or decommissioned.
Automated tiering is a defining capability of modern distributed storage solutions. Data is classified by access frequency and automatically moved between storage tiers — NVMe SSDs for hot data requiring sub-millisecond latency, SAS or SATA HDDs for warm data accessed regularly but not requiring maximum performance, and object storage (cloud or on-premises) for cold data that is retained for compliance or analytics but rarely accessed. Tiering decisions are made by the storage management plane based on access patterns, freeing administrators from manual data placement decisions.
Capacity management in distributed storage is fundamentally different from traditional storage. Adding capacity to a distributed storage system means adding nodes to the cluster. The cluster’s distribution algorithm automatically rebalances data across the expanded node set, filling new nodes without administrator intervention. This linear scalability — where adding nodes adds both capacity and aggregate throughput proportionally — is the defining operational advantage of distributed data storage over centralized storage architectures that require disruptive forklift upgrades to expand.
Data lifecycle policies automate compliance retention, tiering transitions, and deletion based on configurable rules. Object-level lifecycle policies (standard in S3-compatible distributed object storage) define when objects transition from one storage class to another and when they expire — automating the movement of aging data from high-performance distributed block or file storage to lower-cost distributed object storage to cloud archive without manual intervention.
StoneFly’s storage portfolio covers every tier of distributed data storage — unified block, file, and object storage; hyperconverged infrastructure; dedicated scale-out NAS; distributed block storage; and compact mini appliances that bring the same enterprise capabilities to space- and budget-constrained environments. Every platform is powered by StoneFly’s patented StoneFusion 8th-generation storage virtualization software and includes built-in Air-Gapped Vault with WORM immutability for ransomware protection.
The StoneFly Unified Scale-Out (USO) appliance is a single platform that simultaneously delivers SAN block storage (iSCSI and Fibre Channel), NAS file storage (NFS and SMB/CIFS), and S3-compatible object storage — eliminating the need to manage separate block, file, and object storage systems. The USO is the distributed storage foundation for enterprises that need all three storage types from unified, scale-out infrastructure.
The USO scales to 128 nodes, each supporting up to 256 drives, with capacity and aggregate throughput growing linearly as nodes are added. Automated tiering across NVMe, SAS, and cloud storage moves data between performance tiers based on access frequency without administrator intervention. The USO integrates with VMware, Hyper-V, KVM, Citrix, and Proxmox hypervisor environments and is compatible with Veeam, HYCU, Rubrik, Commvault, and Veritas backup platforms.
The StoneFly Unified Storage and Server (USS) is StoneFly’s hyperconverged infrastructure (HCI) appliance, consolidating server, virtualization, storage, and networking into a single turnkey system. The USS integrates award-winning block, file, and S3 object storage with compute and hypervisor functionality, removing the operational and cost overhead of managing separate compute and storage infrastructure.
The USS supports VMware, Hyper-V, KVM, Citrix (XenServer), and Proxmox, and is available in single-node, dual-node cluster, scale-out, and high availability configurations. Clustering is pre-configured and ready to activate, allowing administrators to scale out compute and distributed storage simultaneously as workloads grow. NVMe, SSD, and SAS storage options allow performance tuning to match workload requirements.
StoneFly’s dedicated Scale-Out NAS (SSO) appliance delivers distributed file storage optimized for shared enterprise workloads — media production, high-performance computing, content repositories, and any environment where multiple clients need simultaneous, high-throughput access to a shared file namespace. The SSO scales from a few nodes to 128 nodes, each supporting up to 256 drives, providing effectively unlimited NAS capacity that expands without disruption.
Built-in RAID within each node and erasure coding across nodes delivers high availability and fault tolerance at the distributed storage level. Cloud connect to Azure, AWS, and S3-compatible clouds enables automated storage tiering and offsite replication. AI-based ransomware detection and immutable file repositories — which cannot be modified, deleted, or overwritten for a defined retention period — protect NAS data from ransomware campaigns that target network-attached storage specifically.
StoneFly’s SAN storage appliances deliver distributed block storage via iSCSI and Fibre Channel protocols, providing the sub-millisecond latency and consistent IOPS that databases, virtual machine disks, and high-performance applications require. The SAN platform integrates with StoneFly’s broader unified storage architecture and is compatible with the full range of enterprise backup and virtualization platforms.
The StoneFly M1 is a compact, high-performance mini appliance that delivers the same distributed storage capabilities as StoneFly’s full-scale platforms — configurable as a SAN, NAS, S3 object storage system, USO unified storage platform, USS hyperconverged infrastructure appliance, or DR365V backup and DR system — in a space- and cost-efficient form factor starting at $1,495.
The M1 is powered by an Intel 13th Generation 14-core processor, supports up to 96GB of memory, and provides dual-channel 20/40Gbps storage connectivity and multiple 10GbE SFP+ ports, with optional 10, 40, 100, and 400Gbps network expansion. It supports iSCSI, Fibre Channel, NFS, CIFS/SMB, and S3 REST API protocols across its deployment modes. The M1 can operate as a single node or in a scale-out cluster configuration starting from three nodes — delivering the same enterprise-grade distributed storage architecture as full-scale StoneFly platforms without the footprint or cost of larger hardware.
-> StoneFly USO: Unified SAN, NAS, and S3 Object Storage
-> StoneFly USS: Hyperconverged Infrastructure Appliance
-> StoneFly Scale-Out NAS Storage
-> StoneFly SAN Storage Appliances
-> StoneFly M1: Mini Storage, HCI, and Backup and DR Appliance
Distributed data storage is not an advanced option for organizations that have outgrown centralized storage — it is the baseline architecture for any enterprise operating at modern data volumes. The combination of scale-out capacity, built-in fault tolerance, parallel access throughput, and geo-distribution capability that distributed storage systems deliver is structurally impossible to achieve with centralized storage, regardless of how much hardware is added.
The architectural choice within distributed storage — file, object, block, or database systems, and which specific implementation — depends on the workload characteristics. High-performance computing and shared file workloads need distributed file systems. AI data pipelines and unstructured data at scale need distributed object storage with S3 compatibility. Databases and virtual machine storage need distributed block storage with low latency. Structured data with distributed query needs distributed database architecture.
For most enterprise environments, the answer is all of the above — which is why unified distributed storage platforms that consolidate multiple storage types under a single management plane, with built-in tiering, replication, immutability, and cloud integration, represent the direction enterprise storage architecture is heading.
Contact StoneFly to discuss how the USO unified distributed storage platform, S3 object storage appliances, SSO NAS, USS HCI, and SAN block storage integrate into your enterprise storage architecture.













Join our mailing list to receive the latest news, updates, and promotions from StoneFly.